Choosing the Best AI Transcription Tool: 2026 Guide
You've probably had this moment already. You finish recording a podcast, interview, lecture, meeting, or YouTube video, then realize the actual work starts after the audio stops. You need captions, notes, quotes, timestamps, highlights, maybe even a summary for a teammate or client.
That's where an ai transcription tool stops feeling like a nice extra and starts feeling like basic infrastructure. It turns spoken content into text you can search, edit, quote, repurpose, and publish without replaying the same file over and over.
The reason these tools are everywhere now isn't hard to see. The global AI transcription market is projected to grow from USD 4.5 billion in 2024 to USD 19.2 billion by 2034, a projected 15.6% CAGR according to Market.us research on the AI transcription market. People aren't adopting transcription software because it sounds futuristic. They're adopting it because audio is slow to work with, and text is fast.
What Is an AI Transcription Tool
An ai transcription tool is software that listens to recorded or live speech and converts it into written text. You give it an audio file, video file, meeting recording, or link. It gives you a transcript you can read, search, copy, export, and often summarize.
The simplest way to think about it is this: it's like having a fast assistant who sits through your recording and types what was said. A modern tool often does more than that. It can separate speakers, add timestamps, create captions, and pull out key points.
That matters if your work depends on spoken content. Podcasters use transcripts to create show notes. Journalists use them to search interviews. Students use them to review lectures. Marketing teams turn webinars into blog posts, clips, and email copy. If you're still new to the basics, this primer on audio transcription fundamentals is a useful starting point.
A lot of people confuse transcription with summarization. They're related, but they're not the same. A transcript is the full text version of what was said. A summary is a shorter interpretation of the important parts. Good tools often provide both, but you should know which one you need before you upload anything.
If you work with video, transcription also sits at the center of captioning and repurposing. This guide to modern video transcription strategies explains how creators use transcripts beyond simple note-taking.
A transcript isn't just a record. It's the version of your audio that you can actually work with.
From Sound Waves to Searchable Text
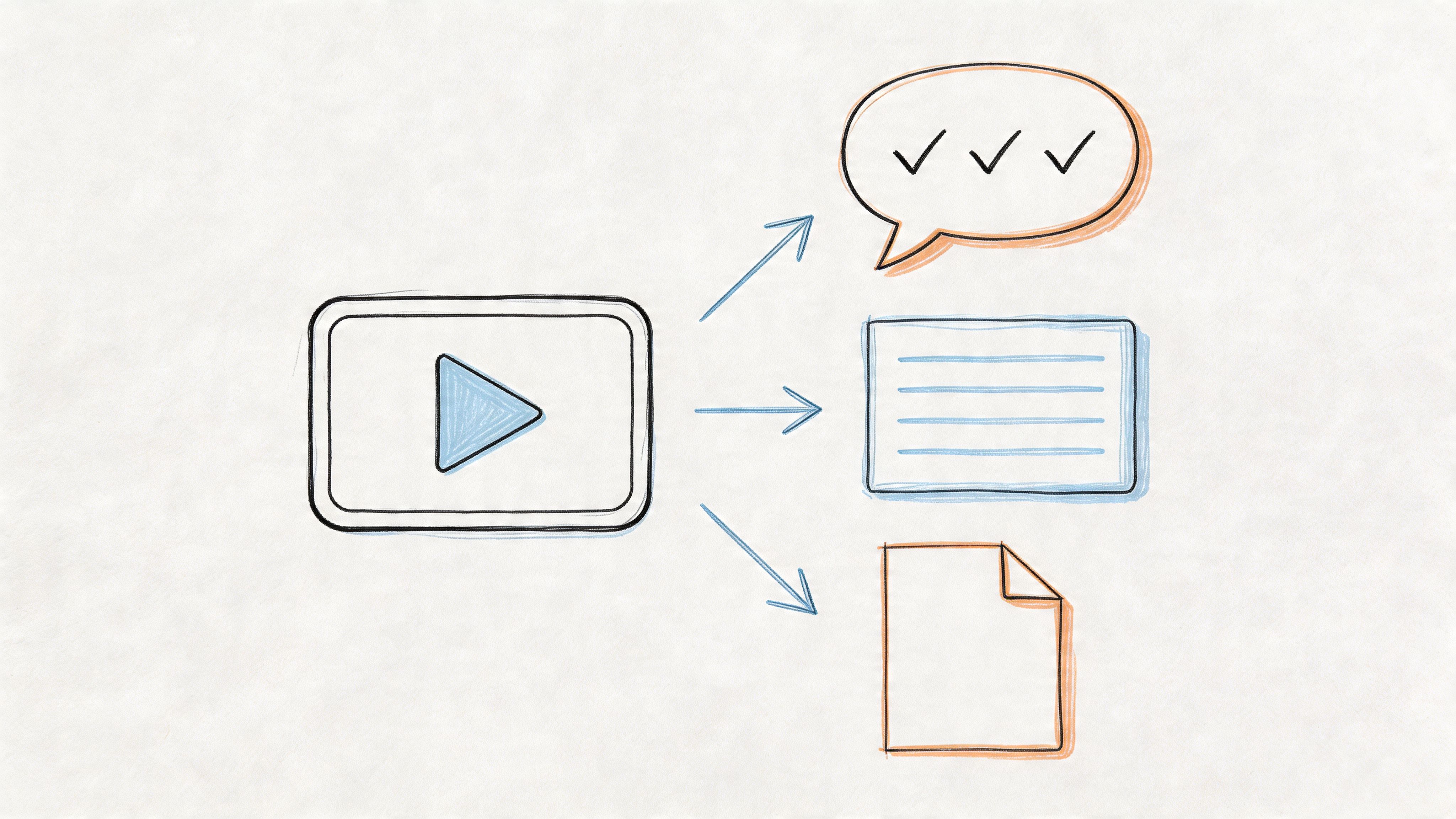
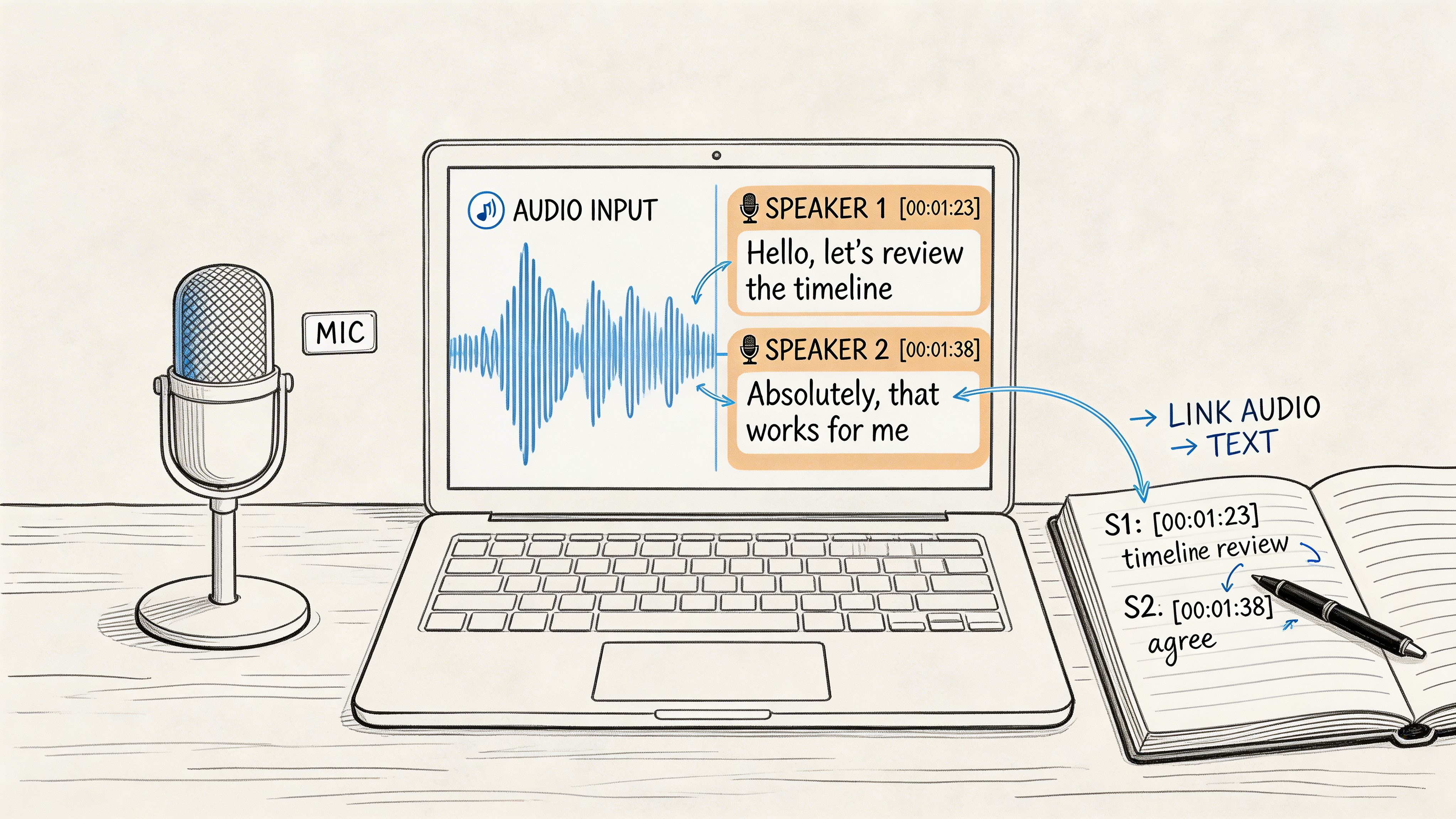
When people first try an ai transcription tool, the result can feel almost suspiciously fast. You upload a file, wait a bit, and suddenly you've got a block of text with speaker names and timestamps. Under the hood, several things are happening in sequence.

A team of digital specialists
I like to explain it as a small digital production team.
The first person on the team handles audio intake. This part grabs the file, checks the format, and prepares the sound for processing. If your source is messy, like a downloaded webinar or a social clip, cleaning up the input before transcription can help. In some workflows, people first extract audio from video with tools built for secure video conversion for professionals, then feed that cleaner audio into the transcription step.
The second person is the speech-to-text engine. This is the core system that maps sounds to words. It doesn't “understand” speech the way a human listener does. It predicts the most likely words based on acoustic patterns and language models. If you want a simple overview of that conversion process, this guide to voice to text AI breaks it down well.
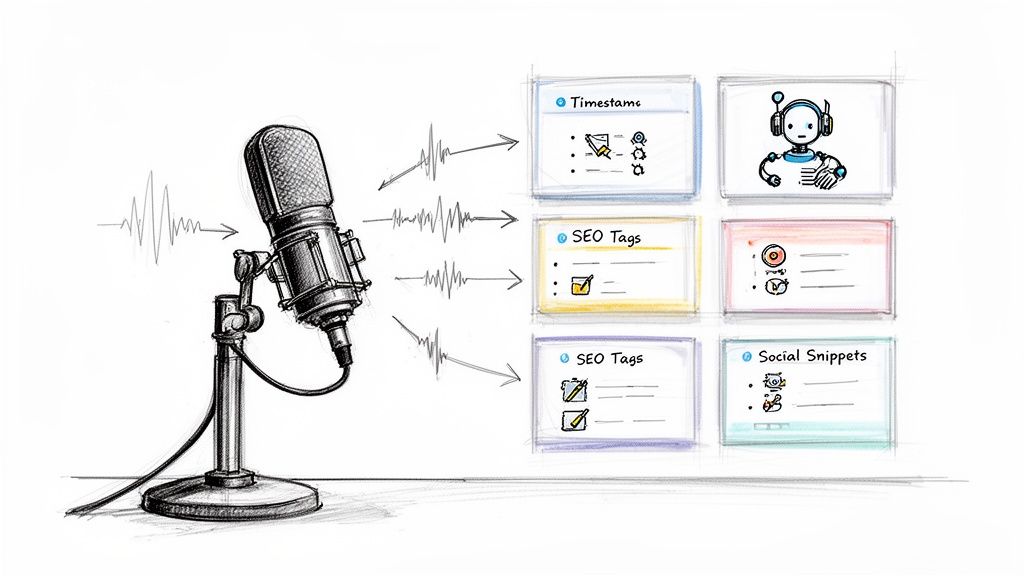
Then a third specialist steps in for speaker diarization. That's the feature that tries to answer, “Who said what?” Instead of one long wall of text, the tool groups speech by speaker and labels the turns in conversation. This is what makes interview transcripts and meeting notes much easier to use.
What happens after the words appear
Once the base transcript exists, another layer improves readability.
That layer often adds punctuation, sentence breaks, and timestamps. Without it, transcripts read like a stream of words. With it, you can jump to a specific moment in the recording, scan for a quote, or turn the file into captions.
After that, many tools apply natural language processing to create summaries, action items, or topic labels. That's why some platforms can answer questions like “What were the main objections in this sales call?” or “Give me the highlights from this episode.”
A simple workflow looks like this:
- Capture the audio from a meeting, interview, video, or voice note.
- Convert sound into words with the speech recognition engine.
- Organize the transcript with speakers, punctuation, and timestamps.
- Make it usable through summaries, exports, captions, or searchable notes.
Why speed changed expectations
The surprising technical leap lies in their speed. According to Guideflow's overview of AI transcription software, platforms like Typist can process audio up to 200x faster than real time, so one hour of recording can become production-ready text in about 18 to 30 seconds.
That speed changes behavior. You stop treating transcription like a special task and start treating it like a default step. Record first. Transcribe immediately. Then decide what to publish, summarize, clip, or archive.
Practical rule: If you create audio or video more than once a week, transcription should sit near the start of your workflow, not at the end.
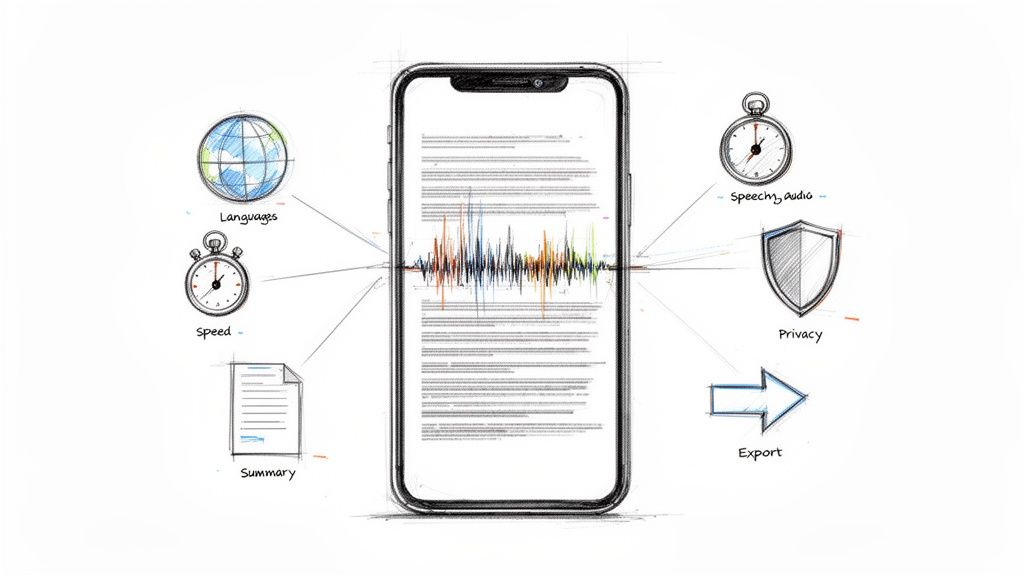
Key Features That Save You Time
The best ai transcription tool doesn't just dump text onto the screen. It removes the little pieces of friction that usually eat your afternoon.

Features that matter in daily work
The baseline has risen. According to Upwork's review of AI transcription tools, speaker diarization and multi-language support are now table-stakes, with platforms supporting 49 to 99+ languages and dialects. Export formats have also standardized around SRT, DOCX, TXT, PDF, and Markdown.
That sounds technical, but the practical impact is simple. You shouldn't have to fight the output.
Here are the features I'd pay attention to first:
Speaker labels that stay readable: If you record interviews, group calls, or podcasts, this is the difference between “usable” and “annoying.” A transcript with clear speaker turns is much easier to quote and fact-check.
Clickable timestamps: These let you jump from a line of text back to the exact audio moment. If you edit video, review interviews, or verify a quote, this saves real time.
Flexible exports: SRT matters for captions. DOCX helps when an editor wants a familiar format. Markdown is useful if you publish online or work in Notion, Obsidian, or a CMS.
Language coverage: If your work crosses markets, accents, or bilingual interviews, broad language support isn't a bonus. It's basic risk management.
Custom vocabulary or dictionaries: This matters more than is often acknowledged. Brand names, product terms, guest names, and industry jargon are where many transcripts go off track.
Small conveniences that become big ones
Some features look minor until you use them for a month.
Interactive search is one. Instead of replaying a one-hour episode to find the moment someone mentioned pricing, you search the transcript and jump right there. Summaries are another. They won't replace review, but they help you orient yourself before editing.
If your work includes voice-heavy communication, adjacent workflows matter too. For example, teams that deal with recorded messages often benefit from systems that connect voicemail and text-based follow-up. SnapDial's article on voicemail email integration is a good example of how transcription fits into broader communication workflows.
A quick way to judge usefulness is to ask one question: does this feature reduce replay? If it helps you stop re-listening to the same file, it probably earns its place.
| Feature | Best use case | Time-saving effect |
|---|---|---|
| Speaker labels | Interviews and meetings | Faster review and quoting |
| Timestamps | Editing and verification | Easy jump-back to source audio |
| Export options | Publishing and sharing | Less format cleanup |
| Language support | Global content workflows | Fewer tool switches |
| Custom terms | Technical or branded content | Fewer correction passes |
Putting AI Transcription to Work
The easiest way to understand an ai transcription tool is to watch what happens when different people use the same transcript differently.

Three common workflows
A podcaster records a guest episode in the morning. By lunch, the transcript is already doing three jobs. It becomes show notes, quote pull-outs for social posts, and caption text for short clips. The transcript isn't the final product, but it becomes the raw material for everything else.
A journalist handles the same type of file differently. The transcript becomes a searchable interview log. Instead of scrubbing through audio for one sentence about a timeline or allegation, they search key terms, return to the source moment, and verify the wording before publication.
A student uses the transcript in a more personal way. They upload a lecture recording, then highlight sections they didn't fully understand in class. Later, they review the transcript like study notes, not just as a word-for-word record.
Where teams get the biggest lift
Business teams often get the broadest workflow gain because they create spoken content constantly without treating it like an asset.
- Meeting notes: Teams can turn discussions into action items and decision logs.
- Training content: Internal calls become searchable reference material for onboarding.
- Customer research: Interview transcripts make themes easier to spot across calls.
- Marketing repurposing: Webinars become articles, FAQs, captions, and email copy.
If you can search your conversations, you stop losing ideas inside recordings.
The hidden pattern across all these use cases is the same. The transcript shortens the distance between recording something and doing something useful with it.
Evaluating and Choosing Your Transcription Tool
Most transcription tools look similar on the landing page. Upload file. Get text. Export. Maybe summarize. The important differences show up later, when the audio is messy, the accents vary, the conversation is sensitive, or the transcript is being used for published work.
Start with reliability, not features
A long feature list can distract you from the question that matters most: Can you trust the output enough for your use case?
Marketing language around accuracy can be slippery. A tool may perform well on clean, single-speaker audio and struggle on a panel discussion, a street interview, or a noisy livestream. That's why your own test files matter more than polished demos.
For higher-stakes work, I'd evaluate in this order:
Accuracy on your actual audio
Don't test with ideal files only. Use a real interview, meeting, or episode with interruptions, crosstalk, and names that matter.Accent and language fit
Broad language support is useful, but what matters is whether the tool handles your audience, guests, and team.Privacy and compliance posture
If you work with client calls, research interviews, internal meetings, or anything sensitive, look closely at file handling and retention.Workflow integration
A transcript you can't move into your editor, caption workflow, or note system creates extra work.Export quality
Good exports save cleanup time. Bad exports create hidden labor.
The hidden risk most buyers miss
One issue doesn't get enough attention outside specialist discussions: hallucination.
In transcription, hallucination means the system inserts words or phrases that were not spoken. According to Sonix's roundup of automated transcription statistics, roughly 1% of Whisper transcriptions contain entirely hallucinated phrases or sentences, and about 38% of those hallucinations include explicit harms.
That matters a lot if you publish, quote, document, or research from transcripts. A transcript can look polished and still contain something nobody said.
For journalists, researchers, and anyone working with interviews, this changes the workflow. You can't treat the transcript as final source material on sight. You have to treat it like a draft linked to the original audio.
Check this first: Any quote, claim, name, date, or sensitive statement should be verified against the source audio before you publish or rely on it.
What a careful buying process looks like
I'd avoid choosing a tool just because it's popular or bundled with another platform. Instead, create a small scorecard and test a few files across the same criteria.
| Evaluation Criterion | What to Look For | Why It Matters |
|---|---|---|
| Accuracy | Performance on your real recordings, not just clean samples | Determines how much editing and verification you'll need |
| Speaker handling | Clear separation of multiple voices | Critical for interviews, podcasts, and meetings |
| Language support | Coverage for the languages and dialects you actually use | Reduces failure on multilingual or accented audio |
| Privacy | Clear processing and retention practices | Important for confidential or regulated material |
| Export formats | SRT, DOCX, TXT, PDF, Markdown, and workflow-friendly outputs | Prevents manual reformatting |
| Search and navigation | Timestamps and text-audio linking | Speeds up review and fact-checking |
| Summary tools | Useful summaries without replacing the source transcript | Helps triage long recordings |
A practical test you can run this week
Use the same short batch of files across every tool you're considering. Include:
- A clean solo recording: This shows baseline performance.
- A two-person conversation: This tests speaker separation.
- A noisy or imperfect clip: This exposes where the tool breaks.
- A jargon-heavy sample: This tests names, terms, and context.
Then review with a red pen mindset. Where does it mishear? Where does it overconfidently invent? Where does the export create friction? That process will tell you more than any homepage promise.
An Example in Action Whisper AI
One way to make the evaluation criteria concrete is to look at a real platform through that lens instead of through marketing copy alone.
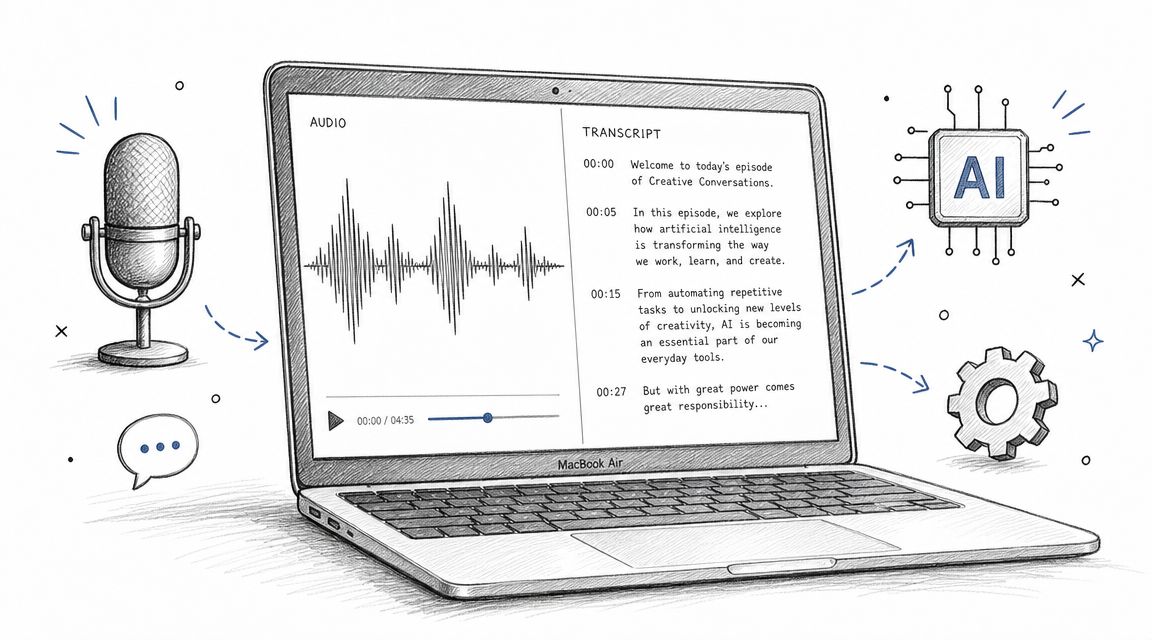
Take Whisper AI for transcription workflows as an example. It processes audio, video, and social clips into searchable text, detects speakers, adds timestamps, generates summaries and bullet highlights, and exports to formats such as Google Docs, Word, PDF, TXT, and Markdown. It also works across 92+ languages, which is useful when your content pipeline isn't limited to one audience or one type of recording.
That combination matters because a tool becomes more useful when it can stay inside the whole workflow. You upload once, review the transcript, pull a summary, export the format you need, and move on. You're not stitching together three separate apps just to get from recording to usable text.
A product example is most helpful when you compare it to the checklist above:
- Reliability fit: It combines multiple models rather than treating one transcript output as unquestionable.
- Speaker and timestamp support: Useful for interviews, podcasts, and meetings where review speed matters.
- Export flexibility: Important if one transcript needs to become captions, notes, and written content.
- Privacy posture: Relevant when the files contain internal or sensitive material.
- Language coverage: Helpful for global teams, creators, and researchers.
If you want to see a tool walkthrough in a more visual format, this video gives a quick sense of how the workflow can look in practice.
The bigger lesson isn't that one platform magically removes all review work. It's that a good ai transcription tool supports the way you work. It should help you move from recording to captioning, note-taking, editing, summarizing, or publishing with less friction and with a healthy amount of skepticism where accuracy matters most.
If you want a practical tool for turning audio, video, and clips into searchable transcripts, summaries, and export-ready files, take a look at Whisper AI. It fits the kind of real production workflow this article focused on: upload once, review carefully, export what you need, and keep the original audio close for anything important.