A Guide to Qualitative Research Transcription That Works
Qualitative research transcription is the essential process of converting spoken words from interviews, focus groups, and observations into accurate, written text. Think of it as the bridge between raw conversation and deep analysis—it’s how you make your audio and video data searchable, code-able, and ready to reveal the themes and patterns hidden within your participants' stories.
Why Great Transcription Is More Than Just Typing
Many researchers view transcription as a tedious chore to get through before the real work of analysis begins. But from my experience, that perspective misses the point. Qualitative research transcription isn't just a clerical task; it’s the first step in your analysis. It lays the very foundation for your entire study.
This is where you capture the authenticity of what people are saying. Every pause, laugh, or moment of hesitation is a data point. These nuances reveal much more than words alone, offering a glimpse into emotions and underlying meanings that a simple summary would completely miss. Whether you're a PhD student performing discourse analysis or a UX researcher pinpointing customer pain points, the transcript is your ground truth.
How Your Transcription Approach Shapes Research Outcomes
The method you choose for transcription isn't just about speed or cost—it directly influences the quality and type of data you end up with. Your choice can either limit or expand your analytical possibilities. Here's a quick comparison to help you understand the impact from the start.
As you can see, there isn't a single "best" method. The right approach depends entirely on your research goals, timeline, and budget. The key is to make a conscious choice rather than simply defaulting to what seems easiest.
The Big Shift from Manual Labor to Smarter Workflows
Not long ago, transcription was a grueling, manual process. Researchers often spent hours transcribing a single one-hour interview, creating massive bottlenecks that limited the scope of their studies.
Thankfully, that’s changing. The global AI transcription market is projected to grow from $4.5 billion in 2024 to an incredible $19.2 billion by 2034. This explosion tells a clear story: researchers are embracing AI-powered tools like Trint and Otter.ai for their speed and efficiency. You can explore more of these interview transcription trends to see just how significant this shift is.
This isn't just about saving time. It’s about being able to manage and analyze qualitative data at a scale once unthinkable, transforming a dreaded task into a streamlined part of the research workflow.
The goal is to reframe transcription not as a chore to be completed, but as a critical analytical tool that directly shapes your research outcomes. It's the first, and arguably most important, step in making sense of human experience.
Ultimately, whether you use a meticulous manual process or a slick AI-assisted workflow, the quality of your transcript dictates the depth and integrity of your findings. A sloppy transcript leads to a shaky analysis. A precise, thoughtfully prepared transcript, however, unlocks the subtle insights hiding in your conversations, setting you up for credible, impactful research.
Setting the Stage for a Flawless Transcription
The quality of your final transcript is often decided long before you hit the record button. I've learned this the hard way: a few extra minutes spent on your recording setup can save you hours of agony trying to decipher muffled audio later. A clean, clear recording is the single most important factor for accurate qualitative research transcription.
It starts with your gear. While a high-end digital recorder is a great tool, it's not always necessary. Modern smartphones have surprisingly capable microphones, but their performance depends heavily on the environment. Understanding the basics of Speech to Text technology can help you capture audio that transcribes well, no matter what device you use.
The goal is to capture every word as cleanly as possible. This means thinking about your entire workflow from the beginning—from the recording all the way through to your final analysis.
As this flowchart shows, transcription is the critical bridge between gathering raw data and pulling out meaningful insights.
Creating the Ideal Recording Environment
Where you record has a massive impact on your audio quality. A bustling café might seem relaxed, but the background clatter of an espresso machine can make parts of your recording unusable. Ambient noise forces transcription software—and human transcribers—to guess, and guessing introduces errors.
Always aim for a controlled setting.
- Find a quiet room. Look for a space with minimal echo. Rooms with soft furnishings like carpets, curtains, or couches are perfect because they absorb sound and reduce reverberation.
- Run a quick test. Before your participant arrives, record yourself talking for 30 seconds. Listen back with headphones. Can you hear a faint buzz from the lights or the hum of an air conditioner? These are the little things that cause big headaches later.
- Think about mic placement. Position the microphone closer to your participant than to any potential source of noise. If you're using a single omnidirectional mic for a group, place it in the middle of the table.
This might sound like common sense, but in the rush to start an interview, it’s one of the easiest—and most costly—steps to forget.
Guiding Participants for Clear Audio
As the researcher, you can actively guide the conversation to produce a cleaner recording. Your job isn't just to ask questions; it's to manage the dialogue for the sake of the transcript you'll be working with later.
It's worth remembering that the person transcribing your audio wasn't in the room with you. They depend entirely on what they can hear to figure out who is talking and what’s being said. Your moderation makes their job—and your eventual analysis—infinitely easier.
One of the biggest challenges, especially in focus groups, is cross-talk—when multiple people speak at once. You have to gently steer the conversation to encourage one person to speak at a time. A simple phrase like, "That's a great point, Sarah. Let's hear what John thinks about that," can work wonders.
The Ethical Foundation: Informed Consent
Finally, and most importantly, you must address the ethics before you hit record. Obtaining informed consent is non-negotiable. This means explicitly telling participants that you'll be recording the session and that the recording will be transcribed.
Your consent form should clearly state:
- That the interview will be recorded.
- How the recording and transcript will be used for research.
- How their privacy will be protected, usually through anonymization.
- Who will have access to the data.
This isn’t just about ticking a box; it’s about building trust and ensuring your research practices are solid. Our guide on how to properly transcribe an interview offers more detail on both the mechanics and ethics. By setting the stage correctly, you guarantee the data you collect is not only clear but also ethically sound.
Choosing Between Verbatim and Intelligent Transcription
Once you have a clean audio recording, your next major decision is the style of your transcript. This isn't just a formatting choice; it fundamentally shapes how you can analyze your data. The two main options are full verbatim and intelligent verbatim, and the right one depends on what you want to learn from your research.
Think of it as the difference between a raw camera reel and a polished documentary. The raw footage captures everything—the shaky camera, the director shouting off-screen. The documentary tells a clear, focused story. Neither is inherently better; their value depends on the story you need to tell.
When Every Sound Matters: The Power of Full Verbatim
Full verbatim transcription (or strict verbatim) captures every single utterance exactly as it happened. This means you’re not just typing out words; you’re documenting the complete vocal experience of the conversation.
This includes all the small things that color our speech:
- Filler words: um, uh, you know, like
- False starts: "I was thinking about the—well, actually, I decided..."
- Stutters and repeats: "It was a-a-a fantastic idea."
- Non-verbal sounds: [laughs], [coughs], [sighs]
- Pauses: Noted as [pause] or (...)
This might sound like overkill, but for certain types of research, this is where the gold is. A linguist analyzing power dynamics might focus on who uses more filler words. A usability researcher will note a user's hesitation—"um, I think I click here?"—as a direct signal of confusion.
In these situations, how something is said is just as important as what is said. Full verbatim keeps these crucial paralinguistic cues intact, giving you a much richer dataset for a truly deep analysis.
This meticulous approach is essential for:
- Psychological studies where hesitation and emotional cues are key data points.
- Linguistic analysis focused on speech patterns and syntax.
- Legal transcription where a flawless, word-for-word record is required.
- Discourse analysis where conversational flow and interruptions are studied.
The Case for Clarity with Intelligent Verbatim
On the other hand, intelligent verbatim (also called clean read) is all about readability. The transcriber acts like an editor, cleaning up the dialogue to get straight to the point while preserving the original meaning.
The goal is to present the core message without conversational static.
For example, a speaker might say: "So, like, I guess, um, what I'm trying to say is that the, you know, the product was really, really easy to use."
An intelligent verbatim transcript would cut to the chase: "What I'm trying to say is that the product was really easy to use." The meaning is identical, but the delivery is clean and direct.
This style is your best choice when your primary focus is on the ideas and themes within the conversation, not the mechanics of speech. It’s perfect for market research reports, creating blog posts from an interview, or summarizing business meetings. With 74% of businesses using qualitative data to inform strategy, clear transcripts are essential for pulling out customer insights. You can read more about why transcription is so vital for market research.
Matching Transcription Style to Your Research Goals
Deciding between full and intelligent verbatim isn’t just an academic exercise—it directly impacts your workflow. The table below breaks down which style and method fit different research needs.
The right approach to qualitative research transcription is the one that aligns perfectly with your analytical goals. By making a thoughtful choice between verbatim styles, you ensure your final transcript isn’t just a document, but a powerful tool designed to unlock the specific insights you’re hunting for.
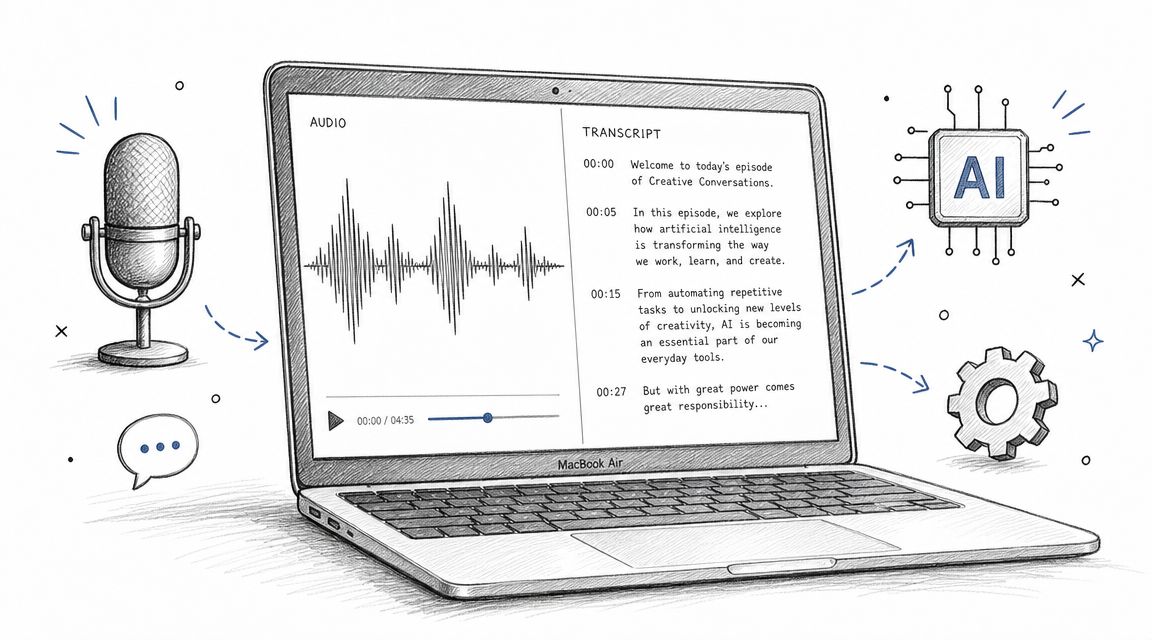
Formatting Your Transcript for Easy Analysis
Even with a perfect recording and transcription method, a final document that's just a wall of text is an analytical nightmare. The whole point of qualitative research transcription is to create something usable for analysis. Your transcript is not the final product; it's a clean, organized dataset ready for you to code and unpack.
Consistent formatting provides the framework that turns a free-flowing conversation into a structured document. This structure allows you and your team to easily see who said what, find key moments, and start pulling out themes. Trying to code a poorly formatted transcript, whether in software like NVivo or with highlighters, is a fast track to frustration.

Create a Simple Transcript Style Guide
Before you start, take ten minutes to create a simple style guide. This is a basic set of rules to ensure every transcript in your project looks and feels the same—a lifesaver when working with a team or just trying to keep your own work organized. It doesn't need to be complicated; it just needs to be consistent.
Here are the essential elements to decide on upfront:
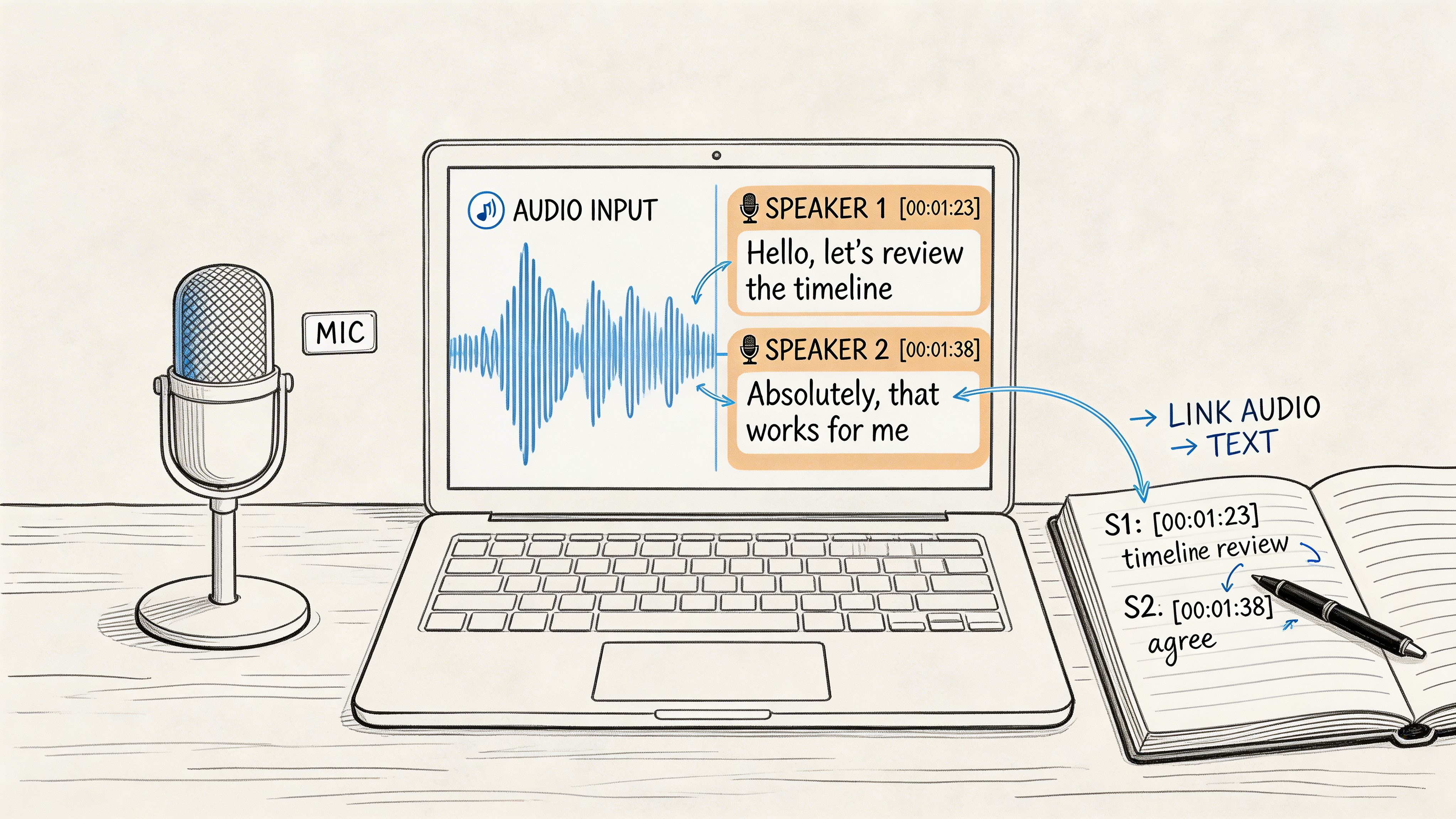
- Speaker IDs: How will you show who is talking? A common method is a bolded name or role followed by a colon (e.g., Interviewer: or Maria:). For focus groups, I recommend generic labels like Participant 1: and Participant 2:, especially since you'll likely need to anonymize the data later.
- Timestamp Frequency: Decide how often to add a timestamp. Some researchers add one every time the speaker changes, which is great for pinpoint accuracy. Others prefer adding them at regular intervals, like every 30 or 60 seconds, to avoid clutter. Pick a frequency that helps you quickly locate the original audio without overwhelming the text. For a deeper dive, check out our guide on transcription with timecode.
- Non-Verbal Cues: How will you note important actions or sounds? The standard practice is to use square brackets for things like
[laughs],[long pause], or[phone chimes]. The key is to only capture what adds meaningful context. You don't need to note every single cough or sigh.
Jotting down these rules from the beginning will ensure your entire dataset is uniform and ready for analysis.
The Non-Negotiable Step: Anonymization
Beyond formatting, you have an ethical duty to protect the people who shared their stories with you. Anonymization is the process of removing or disguising all personally identifiable information (PII) from your transcripts so that no one can be identified by their words.
This isn't just good practice; it's a requirement for most institutional review boards (IRBs) and a core tenet of data protection regulations. Skipping this step is a serious ethical breach.
Anonymization isn’t just about protecting your participants; it’s about protecting the integrity of your research. It builds trust and shows you’re handling sensitive data responsibly, which is fundamental to any credible study.
In practice, this means systematically going through your transcript to find and replace any identifying details. Create pseudonyms or generic placeholders for:
- People's Names: Replace "Jane Doe" with "[Participant 1]" or a pseudonym like "[Sarah]."
- Place Names: Change "I was a manager at Google's Mountain View office" to "I was a manager at [Tech Company] in [West Coast City]."
- Specific Dates: Obscure identifying dates. "My son was born on May 5th, 1998" could become "[Early May]."
- Unique Job Titles: A title like "the lead UX designer for that specific project" may be too revealing. Generalize it to "[Senior Designer]."
This has to be a meticulous process. A good workflow is to run a "find and replace" for known identifiers first, but always follow up with a careful manual read-through to catch what an automated search can miss.
Turning Your Transcript Text into Meaningful Insights
With a polished, formatted, and anonymized transcript, you're at the starting block, not the finish line. This document is the key to unlocking the rich stories and patterns hidden in your conversations. The next steps bridge the gap between what was said and what it all means.
Before you start categorizing anything, just read. Pour a coffee, sit down, and read each transcript from start to finish. Then do it again. This first pass isn't about analysis; it's about immersion. You want to get a feel for the rhythm of the conversations, the topics that keep popping up, and the emotional currents running beneath the surface.
As you read, keep a notebook open to jot down initial thoughts, gut reactions, and quotes that jump out at you. These "memos" are gold and will guide your more structured analysis later.
The Art and Science of Coding Your Data
Once you have a feel for your data, it's time for systematic coding. In qualitative analysis, coding is simply attaching short, descriptive labels ("codes") to chunks of text. These codes help you organize the data, spot patterns, and build up to bigger themes.
Think of it like organizing a library. You wouldn't leave books in a giant pile. You'd create categories—History, Sci-Fi, Biography. Coding does the same for your interview data, letting you pull related ideas together.
There are two main approaches:
- Deductive Coding: You start with a pre-set list of codes based on your research questions or existing theories. This top-down approach works well when you're testing a specific hypothesis.
- Inductive Coding: You let codes emerge organically from the data. You read the text and create new labels as new ideas appear. This bottom-up method is perfect for exploratory research where you're not sure what you'll find.
Most researchers use a hybrid of both, starting with a few deductive codes but staying open to creating new inductive codes as unexpected themes surface.
How AI Can Jumpstart Your Analysis
That initial coding phase can be a real grind. This is where modern AI tools can be a huge help—not as a replacement for your brain, but as a skilled assistant. Many AI transcription services now include features that can give you a running start on your analysis.
For example, some platforms automatically generate summaries or highlight key topics and frequently used keywords. This can be an amazing way to spot potential codes or themes you might have otherwise missed.
While AI can't replicate the deep, contextual understanding of a human researcher, it excels at identifying broad patterns quickly. Use these automated insights as a starting point to guide your own deeper, more nuanced investigation.
This AI-assisted workflow lets you move faster without cutting corners. The AI handles the heavy lifting of finding recurring phrases, freeing you up to focus on interpreting their meaning and connecting them to the bigger picture. Our guide on how to analyze qualitative interview data has more detailed strategies.
From Transcript to Analysis Software
To manage the coding process effectively, most researchers use Computer-Assisted Qualitative Data Analysis Software (CAQDAS) like NVivo, MAXQDA, and Dedoose. A well-formatted transcript is designed to be pulled directly into these programs.
A typical workflow looks like this:
- Export Your Transcript: Save your transcript in a compatible format like
.docxor.txt. Plain text is often best to avoid formatting glitches. - Set Up Your Project: In your CAQDAS tool, create a new project and import all your transcripts as "sources" or "documents."
- Begin Coding: Use the software’s tools to highlight sections of text and apply your codes. The real magic is seeing every instance of a single code across all your interviews, making pattern-spotting incredibly efficient.
This structured process, built on a high-quality transcript, transforms raw conversation into credible, evidence-based findings. The transcript isn't just a record; it's the map that leads you to a deeper understanding.
A Few Common Questions About Transcription
Even seasoned researchers have questions about qualitative research transcription. The small details can have a big impact on your final analysis. Let's tackle some of the most frequent questions.
Think of this as a quick reference guide for those "what do I do when..." moments. Getting these things sorted out from the start makes for a much smoother workflow.
What’s a Realistic Turnaround Time for Transcription?
This is probably the most common question, especially with tight deadlines. The honest answer is: it depends on your audio quality and transcription method.
Here's a practical breakdown:
- Doing It Manually: A professional transcriber typically needs about four hours to transcribe one hour of clear audio. Poor audio, thick accents, or overlapping speakers can easily push that to six hours or more.
- Using AI Transcription: A good AI service can transcribe an hour of audio in just a few minutes—often under 10 minutes for a clean recording.
- The Hybrid Approach (AI + Human): This offers the best of both worlds. The AI generates the first draft in minutes, and then a human expert polishes it for accuracy. The process is usually completed within 24 hours.
Should I Just Transcribe Everything Myself?
There's a strong argument for transcribing your own interviews. It forces you to listen closely and become deeply familiar with your data, catching nuances that text alone can't convey. But, and this is a big but, you must be realistic about the time commitment.
Transcribing your own interviews creates an intimacy with the data that's hard to replicate. You hear the hesitation, the conviction, the story behind the words. Just be careful it doesn't completely eat up the time you've allocated for actual analysis.
If you're on a tight schedule or have many interviews, outsourcing or using a reliable AI tool is almost always the smarter move. It frees you up to do what you do best: interpret the data.
How Do I Deal with Multiple Speakers in a Focus Group?
Focus groups can be a goldmine of information but a nightmare to transcribe. People talk over each other, making it tough to track who said what. An AI tool with good speaker identification is a lifesaver here, as it can automatically separate and label voices as "Speaker 1," "Speaker 2," and so on.
Still, AI isn't perfect with crosstalk. A two-pronged approach is best:
- Be a strong moderator: During the session, do your best to guide the conversation so one person speaks at a time. Every little bit helps.
- Plan for a clean-up pass: After the AI runs, listen back to the audio with the transcript. You'll need to assign correct names or pseudonyms (e.g., [Participant A], [Participant B]) to the generic labels and fix any spots where the AI got confused.
This hybrid workflow combines the speed of automation with the human oversight needed for complex, multi-speaker recordings.
Ready to turn your qualitative data into clear, actionable text? Whisper AI offers fast, accurate, AI-powered transcription with automatic speaker detection and summarization features built-in. Stop spending hours on manual work and start your analysis in minutes. Try Whisper AI for free and see how it can speed up your research workflow.