A Complete Guide to Transcription in Qualitative Research
Before you can start analyzing qualitative data, you first need to process the raw material. In qualitative research, that data is almost always spoken—captured in in-depth interviews, dynamic focus groups, or detailed field observations. Transcription is the essential first step of converting those spoken words into a written text ready for analysis.
But this process is much more than just typing what you hear. I like to think of it as a careful act of translation. You're transforming raw audio, with all its nuances and complexities, into a tangible, searchable, and analyzable dataset. This transcript becomes the bedrock of your entire project, the foundation that allows you to systematically code, identify themes, and interpret what your participants have shared.
Understanding the Role of Transcription in Qualitative Research

Imagine a qualitative researcher as a cartographer, but instead of charting land, they're mapping the vast territory of human experience. The audio recordings are like firsthand accounts from explorers who have traveled that land. These stories are rich and full of detail, but without a map, they're just isolated anecdotes—difficult to compare, connect, or understand in a broader context.
This is where transcription in qualitative research comes in. The transcript is the map. It meticulously charts the conversational landscape, documenting every word and nuance. By converting dialogue into a written format, researchers can finally navigate the complex terrain of human thought, emotion, and behavior with real precision.
Why Transcripts Are More Than Just Words
From my experience, a well-prepared transcript isn't just a record of what was said; it's the very architecture needed for deep, systematic analysis. It gives you the power to:
- Organize Data Systematically: Written text is a researcher's best friend. You can easily segment it, apply codes, and sort it into categories using qualitative analysis software.
- Ensure Analytical Rigor: A transcript provides a verifiable, objective record of your data. This creates transparency and allows for easier peer review and validation of your findings.
- Reveal Deeper Patterns: There’s something powerful about reading and re-reading a conversation. It helps you spot subtle themes, interesting contradictions, and linguistic patterns that are nearly impossible to catch just by listening.
- Facilitate Collaboration: Sharing a text document is simple. It allows research teams to discuss, debate, and build a shared interpretation of the data together.
Ultimately, transcription is the bridge between collecting messy, real-world data and uncovering clean, meaningful insights. It transforms fleeting moments of conversation into a permanent, workable dataset you can return to again and again.
A transcript is not the data itself but a representation of it. The act of creating this representation is the first step in analysis, forcing the researcher to engage deeply with the material and make interpretive choices from the very beginning.
The Growing Importance of Accurate Transcription
The need for high-quality transcription has exploded in recent years, both in academia and in the commercial world. The global transcription services market hit USD 31.9 billion back in 2020 and has only continued to grow.
This boom is a direct reflection of how much fields like market research now rely on turning spoken feedback into actionable strategies. A whopping 74% of businesses now use qualitative data to guide their decisions. For anyone conducting interviews—from UX researchers refining a product to sociologists studying communities—accurate transcription is the first and most vital step toward real discovery. You can learn more about the growth of the transcription market and its impact on research at Grand View Research.
Picking the Right Transcription Style for Your Research
Choosing a transcription style isn't just a technical detail—it’s a foundational decision that shapes the very data you'll be working with. The way you turn spoken words into written text directly influences what you can see, analyze, and conclude.
Think of it like choosing the right lens for a camera. A wide-angle lens captures the entire scene with all its context, while a portrait lens focuses tightly on the subject, blurring out the background. Neither is "better," but the one you choose depends entirely on what you want to capture in your picture.
In qualitative research, your choice boils down to a simple question: Are you analyzing what people said, or are you analyzing how they said it? Let’s explore the three main approaches to help you pick the right one for your project.
Full Detail Verbatim Transcription
Verbatim transcription is your wide-angle lens. It captures everything. Every word, every “um” and “uh,” every stutter, every false start—plus non-verbal sounds like laughter, sighs, and audible pauses. It’s a complete, unfiltered record of the audio.
This meticulous approach is crucial when the subtle nuances of speech are part of your data. Researchers in fields like linguistics, psychology, or discourse analysis depend on verbatim transcripts. They need to see a participant’s hesitation, track their use of filler words to gauge discomfort, or analyze the timing of a pause to understand its meaning.
- Best For: Discourse analysis, psychological studies, legal depositions, or any research where non-verbal cues are just as important as the words.
- Key Feature: It captures all verbal and non-verbal sounds, giving you a complete, raw account of the conversation.
Clean and Clear Intelligent Verbatim
Most qualitative researchers, myself included, use intelligent verbatim, also called clean verbatim. This is your portrait lens. It sharpens the focus on the main subject—the core message—by removing distracting background noise. The transcriber edits out all the filler words, stutters, and repetitions that don’t add any real meaning.
The goal is to create a transcript that’s clean, readable, and easy to analyze. It preserves the speaker's authentic words and intent but removes the conversational clutter. If you’re conducting interviews to find key themes or understand user experiences, intelligent verbatim is almost always the right call.
Intelligent verbatim strikes the perfect balance for most qualitative researchers. It respects the speaker’s voice while creating a clean, workable text that’s ready for coding and analysis.
This style is incredibly practical, saving you hours of cleanup time, especially when you're dealing with dozens of interviews.
Specialized Conversational Analysis
For researchers who need to put conversations under a microscope, there are highly specialized systems like Jeffersonian transcription. This method goes way beyond standard verbatim, using a complex set of symbols to document things like pitch, intonation, overlapping speech, and even the precise length of pauses—measured down to tenths of a second.
This incredible level of detail is essential for conversation analysis (CA), where the mechanics of human interaction are the primary focus of the study. It’s a powerful tool, but it’s also highly technical and requires specialized training to create and interpret the transcripts.
Comparison of Transcription Styles in Qualitative Research
To help you decide, here’s a quick breakdown of how these three styles stack up. This table compares their key features, best use cases, and the pros and cons of each, making it easier to see which method fits your research needs.
In the end, choosing your transcription method is a strategic move that sets the stage for your entire analysis. By matching the style to your research questions, you ensure your data is perfectly suited for uncovering the insights you’re looking for. And when you're using transcription tools, especially AI, remember to keep data privacy front and center. Consulting a practical AI GDPR compliance guide is a smart step for ensuring your research remains both ethical and legal.
A Step-By-Step Workflow for Quality Transcripts
Let’s move from theory to practice. A structured workflow is your best defense against inconsistent, inaccurate transcripts that can derail your analysis. Think of it like a recipe for your research—skipping a step can spoil the whole dish.
By carefully preparing your audio, transcribing with a clear plan, and reviewing your work, you build a reliable foundation for uncovering the rich insights hidden in your data. A solid workflow isn't just about accuracy; it's also about upholding the ethical standards at the heart of qualitative research.
Step 1: Preparing for Accurate Transcription
Believe it or not, a high-quality transcript starts long before you type the first word. Great preparation is the secret to a smooth process, saving you countless hours and headaches down the road.
First, focus on getting the best audio quality possible. A clean recording is the single most important factor for accuracy. This means using a good external microphone, picking a quiet spot for your interviews, and always running a quick soundcheck. Trying to transcribe audio filled with background noise or muffled voices is a surefire way to introduce errors.
Next, create a speaker identification key. This is just a simple guide that assigns a consistent label to each person (e.g., "Interviewer," "P1," "P2"). Doing this upfront is a lifesaver, especially with focus groups, and ensures anyone reading the transcript can easily follow the conversation.
This diagram shows how different transcription methods fit into your overall plan, each offering a different level of detail.
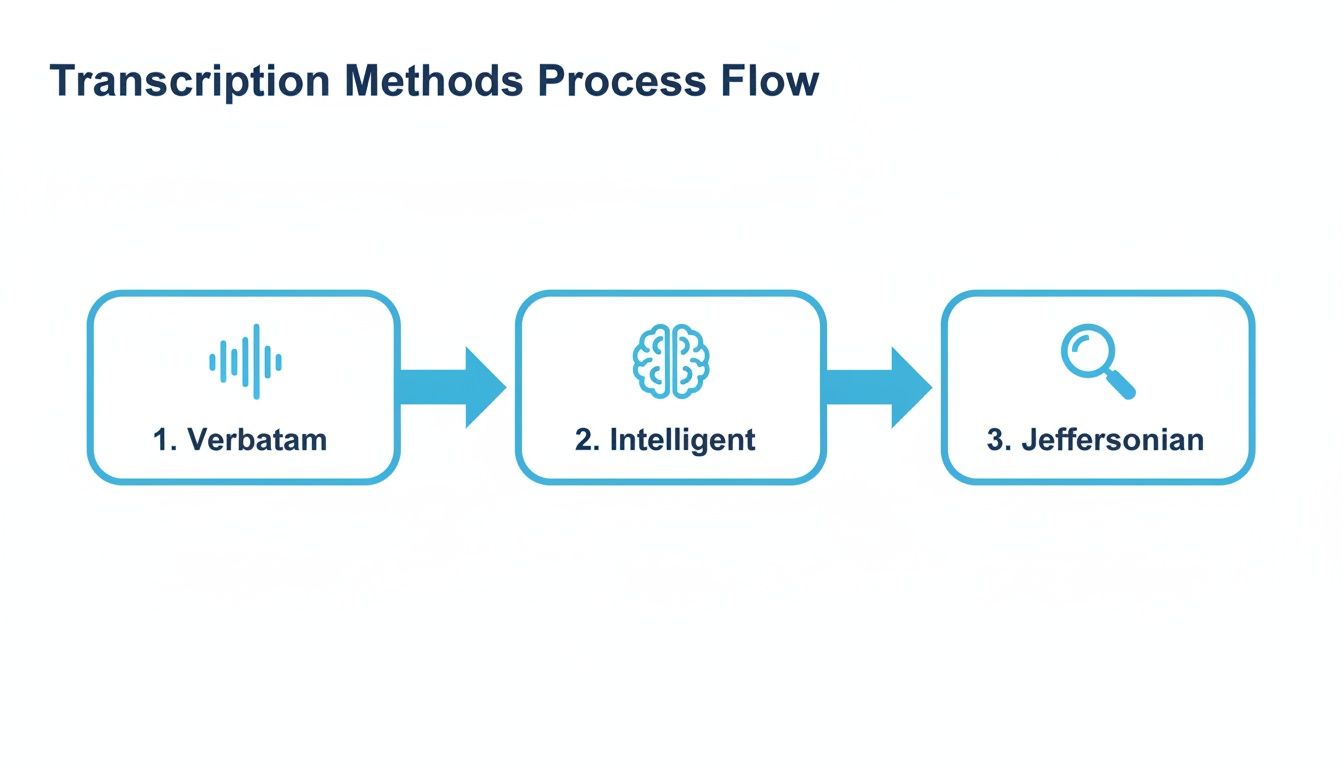
As you can see, your choice of method—whether it’s the all-inclusive Verbatim or the streamlined Intelligent approach—is a core part of your workflow.
Step 2: Executing the Transcription Process
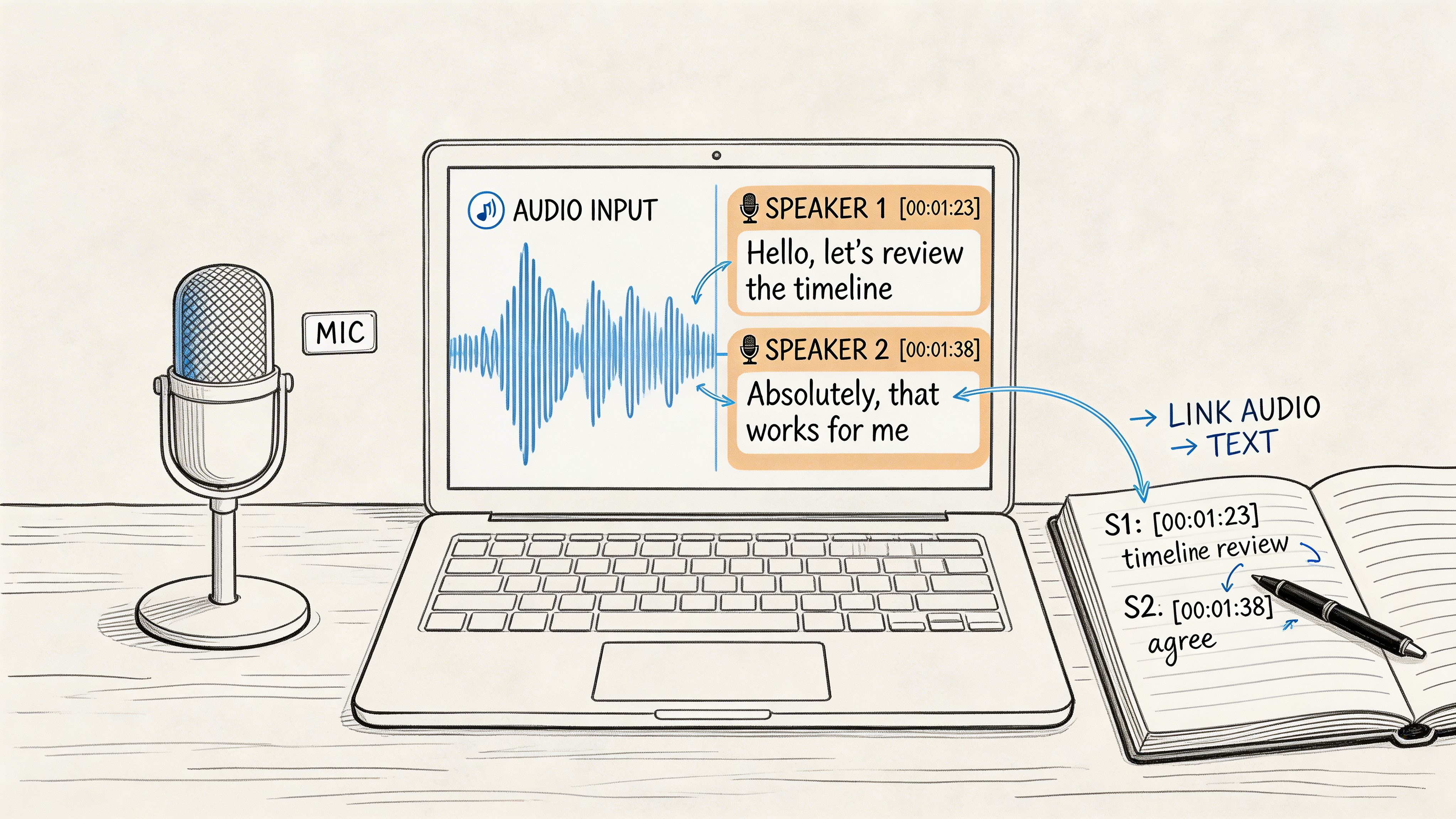
With your clean audio and speaker key in hand, it's time to start transcribing. This stage is all about attention to detail and sticking to your chosen rules. Consistency is key to producing a uniform set of transcripts across your entire project.
One of the most valuable habits I’ve learned is consistent timestamping. Think of timestamps as little bookmarks that link your text directly back to the original audio. I recommend dropping one in every time the speaker changes or at regular intervals, like every minute. This makes finding and verifying quotes during your analysis incredibly easy.
Here’s a quick checklist for this phase:
- Use Clear Speaker Labels: Apply the labels from your key consistently (P1:, Interviewer:, etc.).
- Indicate Non-Verbal Cues: If your analysis requires it, use brackets to note things like
[laughter],[sighs], or[long pause]. - Follow a Style Guide: Decide how you'll handle things like numbers, acronyms, or filler words, and then stick to those rules.
The goal here isn't just to get the words right. It's to create a functional document formatted for systematic coding, one that’s ready to be imported into analysis software like NVivo or Dedoose.
Step 3: Ensuring Ethical Integrity and Confidentiality
The final—and arguably most important—step is protecting your participants. Qualitative research often dives into sensitive, personal territory, which makes ethical data handling non-negotiable. Anonymization is the cornerstone of that responsibility.
Meticulous anonymization means systematically removing or replacing every piece of personally identifiable information (PII) in the transcript. This isn't a quick find-and-replace job; it's a deliberate, careful process.
You need to scrub the text for the following:
- Names: Replace all names with pseudonyms or generic labels (e.g., "[Sarah]" becomes "[Participant A]").
- Locations: Generalize specific places. "The Starbucks on 5th Street" should become "[a local coffee shop]."
- Organizations: Swap company or university names for generic descriptions like "[her employer]" or "[a state university]."
- Dates: Obscure any specific dates that could be used to identify an individual or a sensitive event.
Failing to properly anonymize data is a serious ethical breach that can destroy participant trust and violate institutional review board (IRB) protocols. By building this step directly into your workflow, you ensure every transcript is clean, ethical, and ready for analysis.
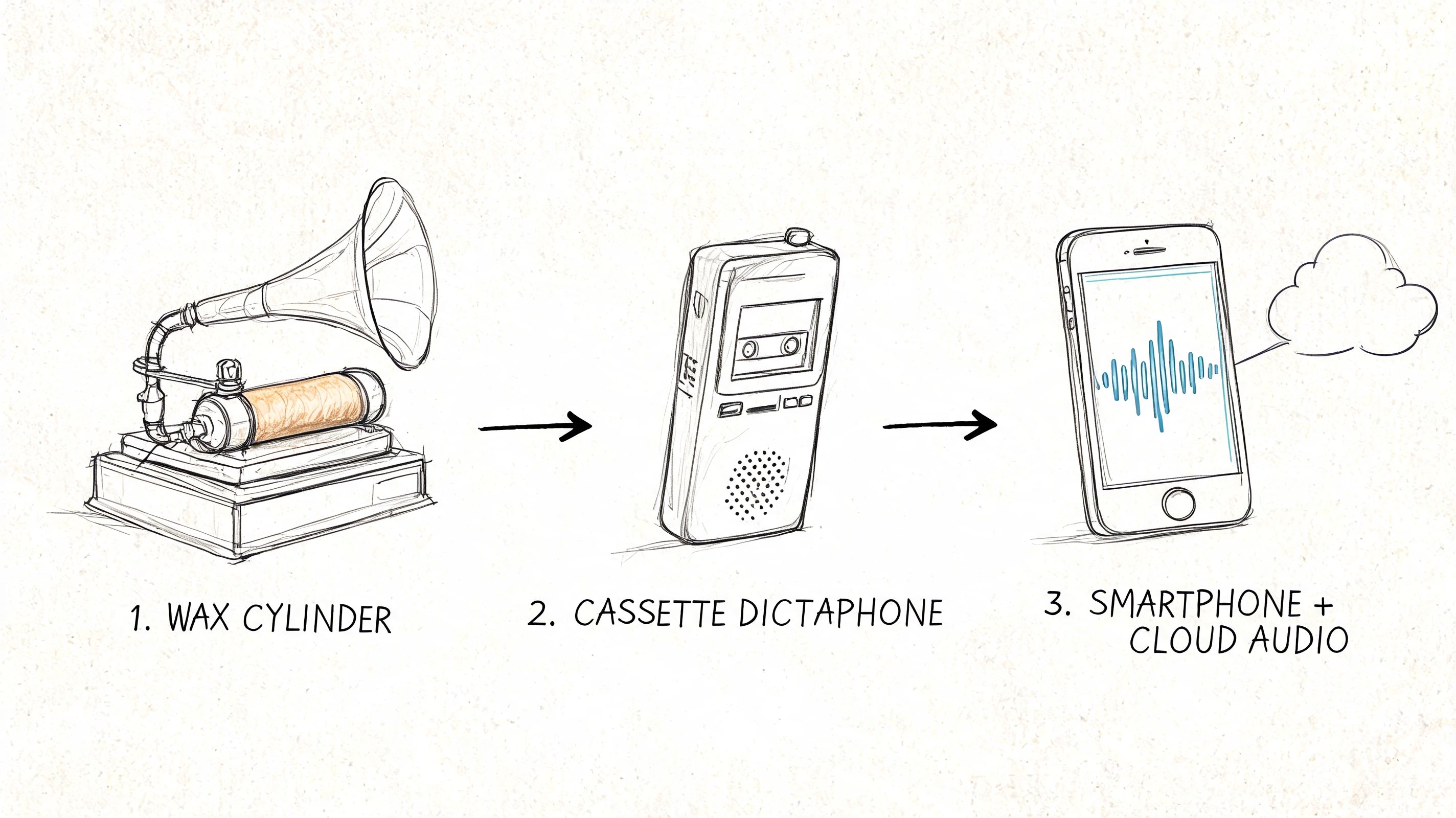
How AI Is Changing the Game for Research Transcription

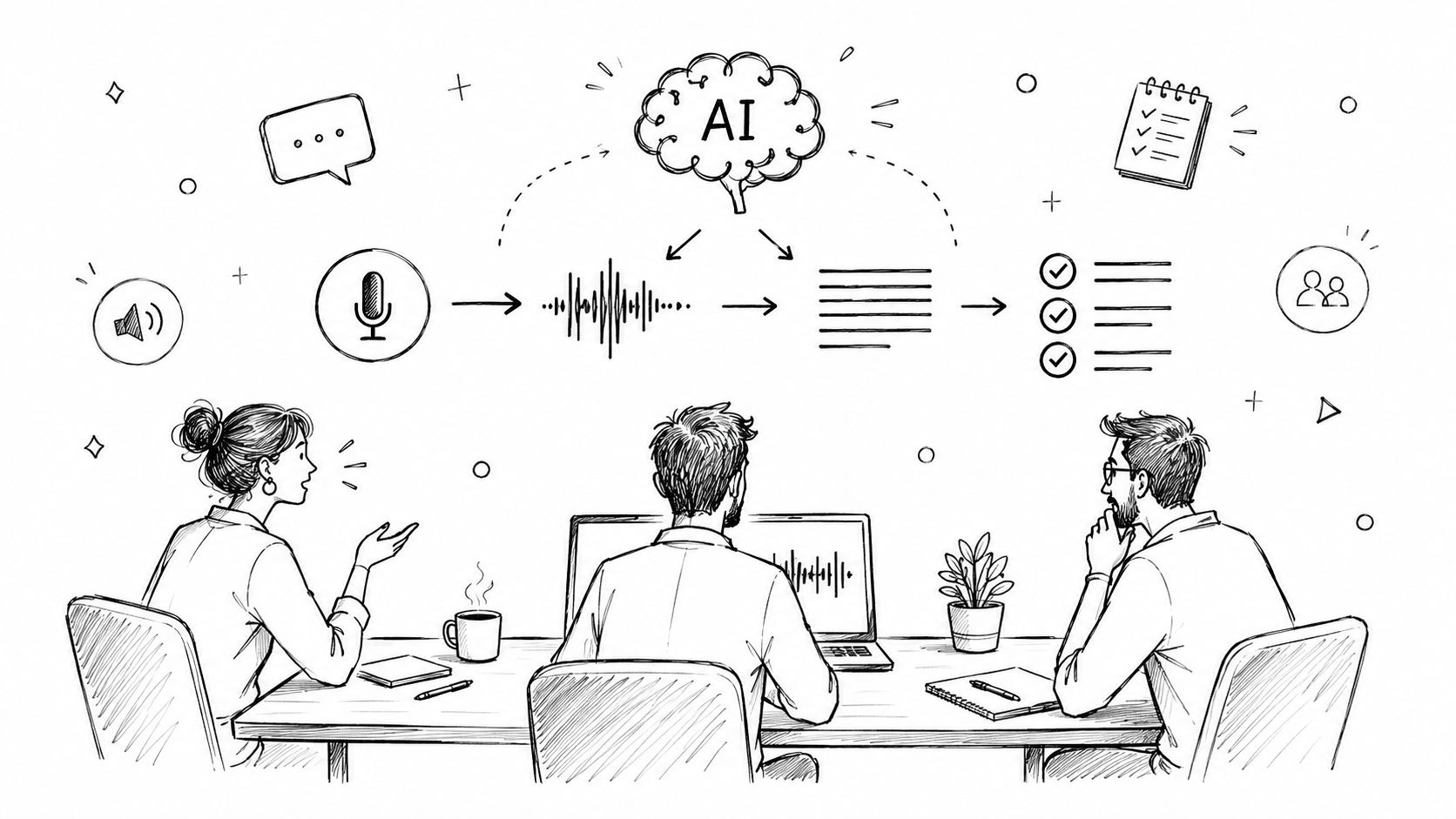
For decades, the slow, painstaking work of manual transcription has been a major bottleneck in qualitative research. Let's be honest—it’s a grind. But artificial intelligence is completely changing that, bringing a new level of speed and efficiency to the process.
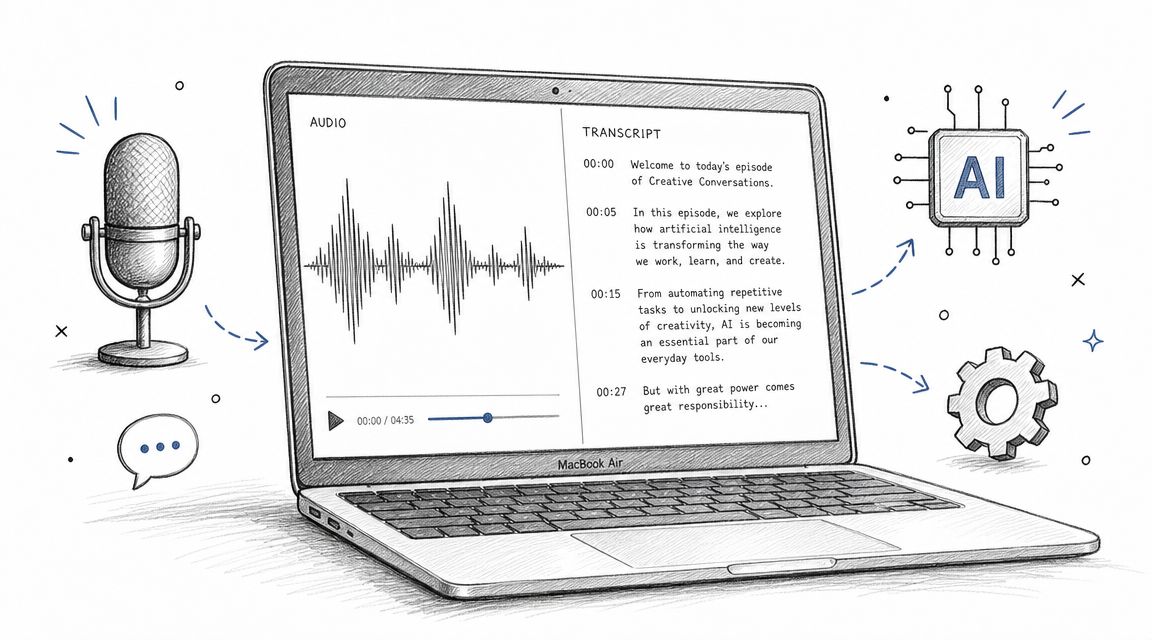
AI-powered tools are now a core part of the modern researcher's toolkit. I think of them as incredibly fast assistants, not full replacements. Platforms built on advanced models like Whisper AI can churn out a complete first draft from an hour-long interview in just a few minutes. This frees you up from the drudgery of typing every single word, letting you focus on the real work: analysis and discovery.
Knowing AI's Role—And Its Limits
AI is a massive leap forward for speed and cost-effectiveness, but it’s vital to understand what it can and can't do. The technology is impressive, but it’s not perfect.
The smartest way to use AI is as a highly capable assistant that produces your first draft. You, the researcher and subject-matter expert, then step in to refine, correct, and contextualize that draft. This ensures the final transcript is 100% accurate and ready for analysis.
It’s a bit like using a calculator for complex math. The machine crunches the numbers instantly, but the mathematician still needs to know the formulas and interpret the results. For a glimpse of this in action, look at the technology behind AI auto-generated captions on social media—it’s the same fundamental speech-to-text concept, great for a first pass.
The New Best Practice: A Human-in-the-Loop Approach
The most effective workflow today is a hybrid model that blends the raw speed of AI with the nuanced understanding of a human expert. This approach has quickly become the new standard for researchers who need to balance speed, cost, and absolute accuracy.
Here’s a breakdown of how this hybrid process usually works:
- AI First Pass: First, you upload your audio file to an AI transcription service. The AI gets to work and generates a rough transcript in minutes.
- Human Review and Refinement: Next, you review the AI-generated text while listening to the original audio. This is where you correct errors, clarify ambiguous phrases, format speaker labels, and apply any necessary anonymization.
- Final Quality Check: A final read-through ensures the transcript is clean, consistently formatted, and perfectly aligned with your research goals.
This blended method is where the magic happens. While automatic tools alone might hit around 86% accuracy, they often miss the subtleties. A human-AI partnership can push that figure to 99%+ accuracy. This combination drastically cuts down on errors and helps you spot key themes faster when prepping data for coding in software like NVivo.
What AI Can't Hear: Navigating the Nuances
While AI is fantastic at capturing clear, straightforward speech, it often stumbles on the very complexities that make qualitative data so rich. When you're in the review stage, you need to keep a close eye on these common trouble spots.
AI systems often misinterpret:
- Strong Accents or Dialects: Regional speech patterns can easily confuse an algorithm, leading to bizarre word choices.
- Overlapping Speech: When participants talk over each other, AI struggles to untangle the voices and might merge sentences or drop words entirely.
- Technical Jargon: Industry-specific terms might be transcribed phonetically but incorrectly (e.g., "fintech" becomes "thin tech").
- Emotional Nuance: AI has no concept of tone. It can't catch the sarcasm, hesitation, or emotional weight behind a statement, which is something a human researcher must interpret and sometimes note.
By handling the initial grunt work, AI gives you back hours of your time. Our guide to AI-powered transcription services digs deeper into how these tools can fit your specific workflow. Ultimately, your expert review is what ensures the final transcript is not just accurate in its words, but completely true to its original meaning.
Preparing Your Transcript for Data Analysis
Getting an accurate transcript back is a huge step, but it’s the raw material for your research, not the finished product. Before you can dive into analysis, there’s a final, crucial stage: preparing that raw text into a clean, reliable, and consistently formatted document. This quality control process is what guarantees the integrity of your findings and stops small errors from turning into flawed conclusions down the line.
Think of it like a chef prepping ingredients before starting a meal. You don't just toss unwashed vegetables into the pot. You meticulously wash, peel, and chop them. In the same way, a transcript needs to be "cleaned" before you can use it to cook up any meaningful analysis. This stage transforms a good transcript into a truly coding-ready document.
The Multi-Pass Review Process
A solid review isn’t just a quick skim. The best approach I've found is a multi-pass process, where you look for different kinds of errors on each pass. Trying to catch everything at once is a recipe for missed mistakes; a systematic review is far more effective.
Start with the low-hanging fruit. Your first pass can be mostly automated by running the spell-check and grammar tools in your word processor. This clears out the obvious typos and clears the clutter, letting you focus on the more important details in the next pass.
Your second pass is where your human expertise comes in. This is a full audio-text comparison. You'll need to play the original recording and read along with the transcript, line by line. This is your chance to confirm that speaker labels are correct, timestamps are accurate, and no critical phrases were misheard—whether by a human or an AI. Pay extra close attention to jargon, names, or any words that sounded ambiguous on the first listen.
The entire point of this review is to create a high-fidelity representation of the original conversation. Every correction you make strengthens the link between your text and the real-world event it captures, which is fundamental to the validity of your research.
Creating a Coding-Ready Document
Once you’re confident the content is accurate, the last step is to get the formatting in order. It needs to be clean and, most importantly, consistent across all of your transcripts. This is absolutely vital for a smooth import into qualitative data analysis software (QDAS) like NVivo or Dedoose, which depend on uniform structure to segment the data correctly.
Here’s a final checklist to run through before you call a transcript "done":
- Consistent Speaker Labels: Is every speaker identified the same way every time (e.g., "P1:", "INT:") not just in this file, but across your entire project?
- Clean Formatting: Have you stripped out any weird characters, extra spaces, or unnecessary formatting that could trip up your analysis software?
- Anonymization Double-Check: Go back one last time. Are all names, locations, and other identifying details properly replaced with their pseudonyms or generic labels?
- File Naming Convention: Does the file have a clear, logical name (e.g., "Interview_P1_2024-10-26.docx") that will make sense when you have a folder full of them?
Running through this checklist ensures your data is robust and trustworthy. After preparing your transcript, you can finally move on to the analysis itself. For a deep dive into that process, check out our guide on how to analyze qualitative interview data to learn how to turn your perfectly prepared text into compelling findings. Investing the time here sets you up for a much smoother and more insightful analysis later.
Common Questions About Research Transcription
Once you start turning audio into text, a host of practical questions always bubble up. Getting a handle on these common hurdles is the key to keeping your project moving forward without getting bogged down in the details.
Think of this section as your go-to troubleshooting guide. Having solid answers ready will help you make smarter decisions about your time, budget, and ethical duties, clearing the path from raw recording to rich analysis.
How Long Does It Take to Transcribe One Hour of Audio Manually?
This is almost always the first question researchers ask, and the answer can be a real eye-opener. For a seasoned professional, the industry standard is a 4:1 ratio. That means one hour of clear, high-quality audio will take about four hours to type out by hand.
But let's be honest—that four-hour estimate is for a perfect world. The reality is that time can easily balloon if your recording conditions are anything less than ideal.
Several things can quickly push that ratio to 6:1 or even higher:
- Poor Audio Quality: A noisy café, a faint microphone, or an echoey room will have you hitting rewind constantly just to make out what was said.
- Multiple Speakers: Trying to track who's speaking in a lively focus group, especially when people interrupt each other, adds a whole new layer of difficulty.
- Strong Accents: If you're not used to a particular accent or dialect, your brain has to work much harder, which slows you down and can introduce errors.
- Technical Jargon: Pausing to look up the spelling of specialized terms from a field you're not an expert in can really add up.
This massive time commitment is exactly why so many researchers are now using a hybrid human-AI approach to get that first draft done faster.
What Is the Best Way to Handle Confidential Information?
In qualitative research, protecting your participants' confidentiality isn't just a "best practice"—it's your most important ethical duty. The gold standard for doing this right is thorough anonymization.
This means you methodically go through the transcript and replace any personally identifiable information (PII) with placeholders or generic labels. It’s a painstaking but essential task to protect the people who trusted you with their stories.
Anonymization is the firewall between your research data and the public. It safeguards participant privacy and upholds the trust they placed in you. It's a non-negotiable step in ethical qualitative research.
When you anonymize, you also need to create a separate, secure "key file" that links the pseudonyms back to the real identities. This file must be encrypted and stored completely separately from your transcripts. And if you're thinking of using a third-party transcription service, you absolutely must confirm they have ironclad security and privacy policies in place, ensuring your data is handled safely and never used for anything else.
Should I Transcribe Interviews Myself or Outsource?
The choice between transcribing your own interviews or hiring it out boils down to a classic trade-off: time versus money. And honestly, there are great reasons to go either way.
Doing it yourself is obviously the cheapest route. It also offers a huge analytical advantage; there's no better way to get intimately familiar with your data than by listening to it over and over. The major downside? It’s an enormous time sink that can derail your entire project timeline.
Outsourcing to a professional service or using an AI tool, on the other hand, can save you a staggering amount of time and often produces a more accurate transcript. This frees you up to focus on the actual analysis. Today, the most popular strategy seems to be a hybrid one: let an AI like Whisper do the heavy lifting for the first draft, then edit it yourself. It strikes a fantastic balance between speed, cost, and staying close to your data.
Ready to reclaim hours of your time and streamline your research workflow? Whisper AI uses advanced AI to generate fast, accurate transcripts from your audio and video files. It automatically handles speaker identification and creates clear summaries, so you can move from raw data to deep analysis in a fraction of the time.