A Practical Guide on How to Analyze Qualitative Interview Data
So, you’ve wrapped up your interviews and now you're sitting on a mountain of audio files and notes. What’s next? Turning those raw conversations into real, actionable insights is where the magic happens. It’s a process of transforming messy, human dialogue into a clear, compelling story.
This isn't just about reading transcripts; from my experience, it's about systematically digging for the patterns, themes, and "aha!" moments hiding in plain sight. Let's walk through the framework that I and other experienced researchers use to make sense of it all.
A Practical Framework for Qualitative Interview Analysis
Diving into hours of interview transcripts can feel overwhelming at first, but a structured approach makes it manageable. The goal is to uncover the rich stories and experiences woven into the conversations you had. Whether you're a UX researcher trying to nail down user pain points or an academic exploring a complex social issue, this process is your guide.
Think of this as your blueprint. Before you even start, it's smart to have a solid conceptual framework in place, which is often guided by your initial research goals, like those from a detailed needs assessment. This keeps your analysis focused.
The entire workflow, from raw data to final report, can be broken down into five core phases.
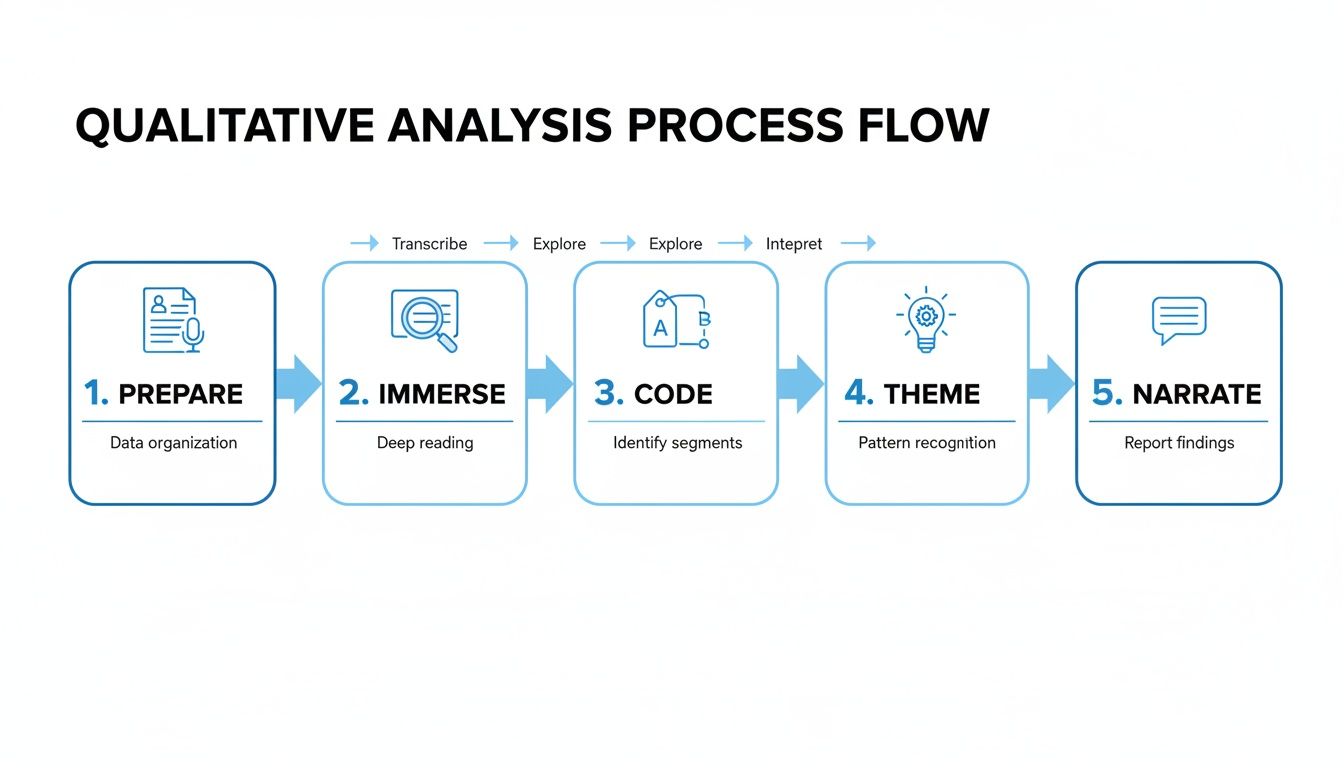
As you can see, each step logically builds on the one before it, taking you from the concrete task of data prep all the way to the more abstract work of interpretation and storytelling.
To give you a clearer picture, here’s a quick summary of the journey ahead.
The Qualitative Interview Analysis Workflow at a Glance
This table breaks down the core stages, showing how you’ll move from raw interview transcripts to the powerful insights you’re looking for.
This structured path ensures your final conclusions are not only insightful but also directly and defensibly tied to the data you gathered.
The Core Stages of Analysis
Getting a handle on what each stage is for helps you stay on track and not get bogged down in the details. While the process can feel a bit circular at times—you might jump back a step as you learn more—these phases provide a reliable roadmap.
Here’s a closer look at what you’ll be doing at each point:
Prepare and Clean Data: This is the foundational work. You'll get your audio transcribed and then meticulously clean up the text. That means checking for accuracy, anonymizing names or sensitive details, and making sure the format is consistent. A clean dataset is non-negotiable for good analysis.
Familiarize and Immerse: Don't just skim. Before you even think about labeling anything, you need to live with the data for a bit. Read your transcripts, then read them again. Listen back to the audio. The goal is to develop an intuitive sense of the participants' worlds, their language, and the overall vibe of the conversations.
Code the Data: Now the real organization begins. Coding is simply the process of attaching short labels (codes) to chunks of text to flag a specific idea, emotion, behavior, or topic. Think of it like tagging. This is how you start breaking down a huge volume of text into smaller, manageable, and meaningful pieces.
Develop Themes: This is where you zoom out. After you've coded your data, you'll start noticing that certain codes seem to cluster together around a larger, central idea. You'll group these related codes to form themes. This is the synthesis phase—where you move from just organizing data to truly interpreting it.
Narrate and Report: Finally, you'll take your well-defined themes and weave them into a compelling narrative. This is your story, backed by powerful, illustrative quotes from your participants. Your job is to communicate what you learned in a way that is clear, credible, and impactful for your audience.
At its heart, qualitative analysis is a process of discovery. It’s less about counting things and more about understanding meaning, context, and the nuances of human experience.
Each of these steps is crucial for conducting a rigorous and trustworthy analysis. If you're curious to learn more about the different analytical approaches you can take, our guide on qualitative research analysis methods is a great next step. Following this structure ensures your insights aren't just guesses—they're firmly rooted in what your participants actually said.
Getting Your Interview Data Ready for Analysis
Before you can even think about finding those brilliant insights, you have to deal with the raw material: your interview recordings. This first stage is all about transforming those audio or video files into clean, usable transcripts. It’s foundational work, and rushing it is one of the most common pitfalls I see.
Think of it like a carpenter prepping wood before building a piece of furniture. You can't just start cutting and joining rough, un-sanded lumber. In the same way, you can't build a sound analysis on a messy, unreliable dataset. Taking the time to get your transcripts right from the get-go saves a world of pain later and ensures your findings are built on solid ground.
The Big Transcription Question: Do It Yourself or Let AI Handle It?
The first choice you'll face is how to get those spoken words into a text document. For a long time, the only real option was to do it manually—a mind-numbing process known for being incredibly slow and often expensive if you outsourced it.
Today, AI-powered transcription tools have completely changed the game. This isn't just about saving a few hours; it's about shifting your energy from tedious administrative tasks to the actual work of thinking and interpreting your data.
Just look at a tool like OpenAI's Whisper, which powers many of the best transcription services available now.
This gives you a sense of how sophisticated these models are. They're built to handle different accents, background noise, and multiple languages, making them incredibly robust. The key takeaway here is that automated systems have reached a level of accuracy that makes them a viable, and often preferable, alternative to the old way.
The time savings are staggering. It’s estimated that manually transcribing one hour of audio can take anywhere from 4 to 6 hours, and that's before you even start coding it, which adds another 3 to 5 hours. If you have 15 interviews, you could easily be looking at over 100 hours of prep work. An automated service can slash that transcription time by 50–80%. That's a huge win.
Polishing and Protecting Your Transcripts
Getting the text down is just the first pass. No transcript, whether from a human or an AI, is perfect right out of the box. You absolutely have to review it for accuracy and consistency. This is your quality control.
Here’s a quick checklist to guide your cleanup process:
- Spot-Check for Errors: AI is good, but it can still mishear jargon, mix up similar-sounding words, or get speaker labels wrong. Do a quick pass with the audio to catch any glaring mistakes.
- Anonymize Everything: Protecting your participants is non-negotiable. Go through and systematically remove or replace any personally identifiable information (PII). This means names, companies, specific locations—anything that could link the data back to an individual.
- Standardize Your Formatting: Make your life easier by ensuring a consistent format for things like speaker labels (e.g., "INT" for Interviewer, "P1" for Participant 1), timestamps, and notes for non-verbal cues like
[laughter]or[long pause]. A clean format makes the text far easier to scan and code.
My Two Cents on Anonymizing: Use consistent pseudonyms for each participant (like "P1," "P2," or fake names like "Anna" and "Ben"). Keep a separate, password-protected file that links the pseudonyms to the real participants. Once the project is done, destroy that key.
This cleanup phase is more important than it sounds. I once worked on a project where a single mistranscribed technical term sent the team down a rabbit hole for two days. We were chasing an "insight" that didn't even exist. A careful review at the start would have saved us a lot of wasted time. Our guide on the role of transcription in qualitative research goes into more detail on best practices here.
By putting in the effort to create a clean, well-formatted, and ethically sound transcript, you’re building the bedrock for a trustworthy analysis. This meticulous prep work means that when you dive into coding, you can be confident you're working with data you can actually trust.
From Words to Patterns: The Art of Coding
Once your transcripts are clean and ready, the real analysis begins. This is where we get into coding—the process of meticulously tagging segments of your text to pull out recurring ideas, themes, and patterns.
Don’t let the term "coding" intimidate you; it has nothing to do with programming. Think of it more like being a detective. You're sifting through evidence (the interview text) and labeling clues. It's an iterative, thoughtful process of reading, re-reading, and labeling that transforms hundreds of pages of raw conversation into a structured, meaningful dataset.
If your interview data is a mountain of LEGO bricks, coding is the act of sorting them by color and shape. It’s the essential first step before you can start building something incredible.

Choosing Your Coding Approach
Before you tag a single word, you need a game plan. There are two main ways to approach coding: deductively or inductively. One isn't better than the other; the right choice boils down to your research goals.
Deductive Coding (Top-Down)
With a deductive approach, you come to the data with a plan. You already have a list of codes based on your research questions or an existing theoretical framework. Your job is to find instances of these concepts in the transcripts.
- When to use it: This is your go-to when you're trying to validate a hypothesis or test a theory.
- Real-world scenario: A marketing team wants to see if their new ad campaign's messaging ("easy to use," "saves time," "affordable") is sticking. They’d create a code for each of those three messages and comb through the interviews, tagging every mention. Simple and direct.
Inductive Coding (Bottom-Up)
Inductive coding is the complete opposite. It's a journey of discovery. You start reading the transcripts with an open mind and let the codes emerge naturally from what people are saying. You create labels on the fly as you spot interesting or recurring ideas.
- When to use it: Perfect for exploratory research where you truly don't know what you're going to find.
- Real-world scenario: A product manager is investigating a sudden drop in user engagement. They have no idea why it's happening. As they read, they start noticing patterns and creating codes like
Frustration with new UI,Missing old feature, andPerformance lagas these pain points surface in the interviews.
In my experience, the best analysis often blends both approaches. You might start inductively to get a feel for the landscape and then switch to a more deductive method to check how often the themes you initially spotted actually appear.
Why You Need a Codebook (And How to Build One)
As you start creating codes, you need a central place to manage them. That place is your codebook. A codebook is simply a document that lists all your codes, defines them clearly, and outlines the rules for applying them.
This isn't just bureaucratic busywork. A codebook is your North Star for consistency, especially if you're working with a team. It prevents "coder drift," where the meaning of a code slowly changes over time or gets interpreted differently by various team members. It’s your single source of truth.
Here’s a practical example of a codebook entry for our product manager's project:
This level of detail is crucial. It ensures everyone on the team applies the Frustration with new UI code in exactly the same way, making your final analysis far more reliable. It also forces you to be disciplined, preventing the creation of a dozen vague, overlapping codes that will only muddy the waters later on. As you analyze qualitative interview data, this document will become your most valuable asset.
Developing Powerful Themes from Your Codes
So, you’ve meticulously gone through your transcripts, and now they're dotted with codes and labels. That’s a huge step, but those codes are just the raw ingredients. The real magic happens next: transforming those individual data points into coherent, meaningful themes that tell the bigger story.
This is where you pull back from the line-by-line detail to see the patterns emerging from the chaos. It’s a bit like being a detective connecting clues. Think of your codes as individual puzzle pieces; now it’s time to start fitting them together.
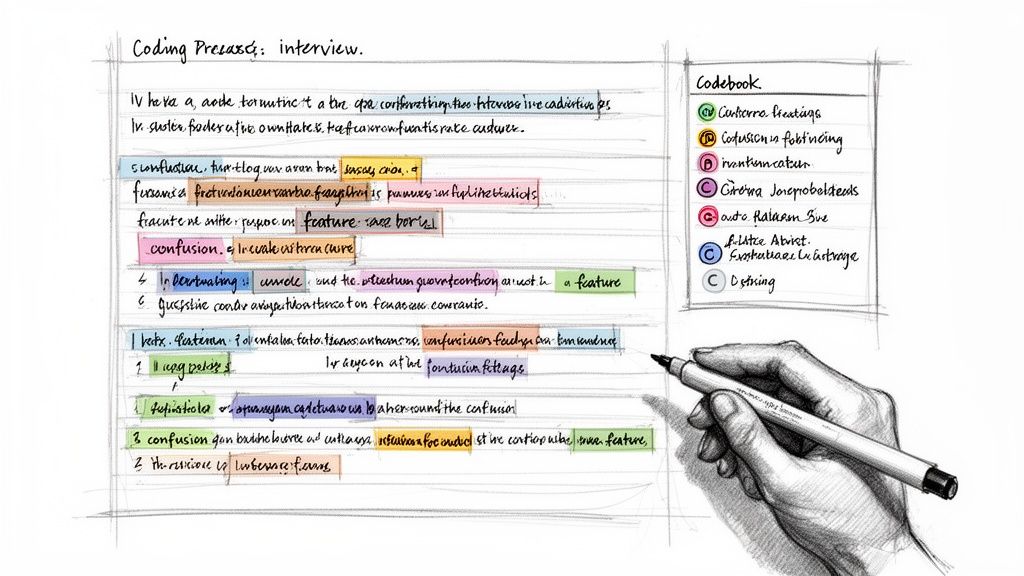
From Code Clusters to Potential Themes
The journey from codes to themes starts by simply looking for relationships. A very practical, hands-on way to do this is to print your codes out or jot them down on sticky notes. Spread them across a big table or a whiteboard and just start physically grouping ideas that feel related.
You’ll see natural clusters start to form pretty quickly. For example, on a recent user research project, I kept seeing codes like confusing checkout process, hidden shipping fees, and website crashes. By physically moving those sticky notes together, a potential theme started to take shape—a broader concept I tentatively called "E-commerce Friction Points."
This clustering process is your first real attempt at synthesis. It’s messy and iterative, and that’s okay. You'll move codes around, scrap clusters, and rename them as you get a better feel for the underlying connections in what your participants are telling you.
Using Thematic Analysis as a Framework
One of the most popular and flexible methods for this stage is Thematic Analysis. It gives you a structured-yet-adaptable way to identify, analyze, and report the patterns (your themes) hiding in the data. There's a good reason it has become a go-to method for researchers.
Between 2007 and 2019, the use of thematic analysis in academic articles shot up from under 50 per year to more than 1,000. Researchers love it because it’s a clear process that’s brilliant for understanding shared experiences. In a typical user research study, it's not uncommon to generate 20 to 60 initial codes from a dozen interviews, which you then distill down into 5 to 10 solid themes. For a deeper dive into this and other methods, GradCoach.com is a fantastic resource.
Here’s what that process generally looks like in action:
- Searching for Potential Themes: This is that clustering stage we just talked about. You’re reviewing all your coded data and spotting those broad areas of potential meaning.
- Reviewing Themes: Once you have a list of candidate themes, it's time to pressure-test them. Go back to your transcripts and ask: Does this theme actually reflect the data? Is there enough evidence to support it? Does it tell a convincing story?
- Defining and Naming Themes: When a theme holds up against the data, you need to articulate what it really means. Give it a clear, descriptive name and write a short paragraph that defines its scope and essence.
Key Takeaway: A theme isn't just a summary of what people said. It's your interpretation—a central concept that organizes and illuminates an aspect of your research topic, backed up by direct evidence from your interviews.
Visualizing Connections to See the Full Story
Sometimes, a simple list of themes doesn’t quite cut it. The richest insights often come from understanding how your themes relate to each other. This is where visual tools can be a game-changer.
Mind mapping is my personal favorite for this. I’ll put my main research question in the center and create branches for each major theme. Then, I’ll add smaller branches off those for the specific codes that build up each theme.
This kind of visual exercise helps you see the architecture of your analysis.
- Does one theme seem to cause or influence another?
- Are two of your themes in direct opposition?
- Is there one central, overarching theme that connects everything else?
In that e-commerce project I mentioned, the mind map was what made it all click. It showed a direct line from the "E-commerce Friction Points" theme to another one I’d identified: "Loss of Trust in Brand." Seeing that link visually made the story a hundred times more powerful. The technical glitches weren't just a minor annoyance; they were actively destroying customer loyalty.
Ultimately, developing powerful themes requires a keen interpretive eye, not unlike the approaches used in literary analysis. It's all about looking past the surface-level words to uncover the deeper meanings, motivations, and narratives that shape people's experiences. This is the moment your analysis shifts from basic organization to true insight.
Ensuring Your Analysis Is Trustworthy
You’ve pulled out your core themes, and the finish line is in sight. But before you declare victory, there's one more critical step: making sure your conclusions are credible and can stand up to scrutiny. A great analysis isn't just about spotting interesting patterns; it’s about proving those patterns are firmly rooted in the data.
Think of this stage as your quality control. It’s where you transform your subjective observations into robust, trustworthy insights that stakeholders can confidently base decisions on. You're essentially building a case for your findings, showing that they aren't just a reflection of your own biases but a true representation of what your participants shared.
Strategies for Building Credibility
Strengthening your analysis is all about systematically challenging your own interpretations to make them stronger. It involves a healthy mix of self-reflection and cross-checking your work against the data.
One of the most powerful techniques here is triangulation. This just means using multiple data sources or methods to see if they all point to the same conclusion. For instance, if your interviews reveal that users are frustrated with a specific feature, do customer support tickets or user session recordings tell the same story? When different sources align, you know you're onto something solid.
Another great reality check is member checking. This is where you go back to your original interview participants and share your preliminary findings with them. You’re not asking them to write the report for you, but simply to confirm that your interpretation accurately reflects what they meant.
Member checking is a gut check for your analysis. It boils down to asking, "Does this sound right to you?" Their feedback can be incredibly validating or help you course-correct before you go too far down the wrong path.
I also swear by keeping a reflective journal. Throughout the analysis process, I jot down my assumptions, personal reactions, and any key decisions I make about codes or themes. This practice forces me to acknowledge my own biases and makes sure they aren’t steering the ship.
Understanding Data Saturation and Sample Size
One of the most common questions I get is, "How many interviews are enough?" In qualitative research, the answer isn't a magic number. It’s about reaching data saturation—the point where new interviews stop revealing new insights. You’re aiming for richness and depth, not just a big sample size.
Fortunately, recent research gives us some helpful benchmarks. A 2024 review found that for identifying common patterns (theme saturation), you might only need around 9 interviews. But if you're trying to gain a deep, nuanced understanding (meaning saturation), you might need closer to 24 interviews.
For most projects, you’ll likely hit a point of diminishing returns somewhere between 15 and 25 well-conducted interviews.
And don't forget, the accuracy of your transcripts is a form of validation in itself. A small error in a transcript can lead to a major misinterpretation down the line. To dive deeper into this, our guide on the importance of proofreading in transcription has some great tips.
By weaving these validation techniques into your process, you build a powerful, credible foundation for your findings. You’ll turn interesting observations into truly defensible insights.
Common Questions About Analyzing Interview Data
Even with a solid plan, you’re bound to hit a few tricky spots when you’re deep in interview transcripts. It happens to everyone. Let's walk through some of the most common questions that pop up for researchers, marketers, and students alike. These answers come straight from the field, based on years of untangling qualitative data.
Getting these details right is what separates a decent analysis from a truly insightful one. The idea is to move forward with confidence, knowing you're handling the messy, complex, and wonderful parts of human data in a thoughtful way.
How Many Codes Are Too Many?
This is easily the most common question I hear, and the honest-to-goodness answer is: there's no magic number. But if you feel overwhelmed, that's your sign you probably have too many.
A huge red flag is when you can no longer hold your codes in your head or easily tell them apart. If you find yourself creating near-duplicates like "Frustration with UI" and "UI Frustrations," you’ve gone too far. Your coding system should be clarifying the data, not making it more complicated.
The best way to rein this in is with a well-defined codebook. Write down what each code means and, just as crucially, what it doesn't mean. That simple discipline is your best defense against code bloat.
What Should I Do with Conflicting Participant Opinions?
First off, finding conflicting views isn't a problem—it’s a goldmine. People have different experiences, and those points of tension are often where the richest insights are hiding. Whatever you do, don't try to smooth them over or pick a "winner."
Your job is to dig into the conflict itself. You might even create a theme around this very tension, maybe something like "A Tale of Two Users: The Split on Feature X." Then, use powerful quotes from both sides to paint a complete picture of the different perspectives. This adds incredible depth to your work and shows you’ve captured the full spectrum of opinion, not just the loudest voice in the room.
Your goal isn't to force consensus. It's to accurately represent the complexity of human experience, which is rarely unanimous. Highlighting disagreement often reveals underlying needs or values that a one-sided analysis would miss.
Should I Code Every Single Sentence?
Absolutely not. Please don't. This is a common misconception that leads directly to burnout and a coding system so unwieldy it becomes useless. Coding is about zeroing in on segments that are significant and relevant to your research questions.
You’re hunting for the good stuff: passages that reveal emotion, express a strong opinion, describe a critical process, or highlight a major pain point. It’s completely normal—and expected—for parts of a transcript, like small talk or stories that go off on a tangent, to remain uncoded. Focus on quality, not quantity. A well-coded dataset highlights the most meaningful parts of the conversation, not every single word.
Manual vs. Software Coding: Which Is Better?
This really comes down to the scale of your project and your own working style. Neither approach is inherently "better," they just serve different needs.
Manual Coding (Pen and Paper, Word/Excel): This is fantastic for smaller projects, say, fewer than 10 interviews. It creates a deep, almost tactile connection to the data. But let's be honest, it becomes a nightmare to manage as your dataset grows.
Software (NVivo, ATLAS.ti, etc.): Qualitative Data Analysis Software (QDAS) is purpose-built for this work. It lets you organize hundreds of codes, instantly search for coded segments, and visualize how themes connect. For any project of a decent size, software will save your sanity and keep your analysis rigorously organized.
Here's how I think about it: you can build a small birdhouse with hand tools, but you’d want power tools to build an actual house. Pick the tool that fits the job. The critical thinking and interpretation are still all you—the software is just there to handle the logistics.
Ready to streamline the first, most time-consuming step of your analysis? Whisper AI transforms your interview recordings into clean, accurate transcripts in minutes, not hours. With automatic speaker detection and concise summaries, you can jump straight to finding insights. Ditch the manual work and focus on what matters. Try Whisper AI for free and see how much time you can save.