How Audio to Text AI Transforms Spoken Words into Data
Ever tried to scribble down notes during a meeting while also trying to pay attention? It's nearly impossible. Now, picture a tool that does the listening and typing for you, capturing every word with near-perfect accuracy. That's essentially what audio-to-text AI is—a smart technology that converts spoken language into text you can edit, search, and share. It’s the magic behind your phone's voice assistant, the live captions on your favorite videos, and those automatic meeting summaries that land in your inbox.
What Is Audio to Text AI
At its core, audio-to-text AI is a form of Automatic Speech Recognition, or ASR for short. Think of it as a bridge between the spoken word and the written word. It doesn't just hear audio; it interprets the sound waves of a human voice and translates them into digital text on a screen.
But this isn't just simple recording and playback. The AI models behind this tech have been trained on massive libraries of human speech, learning to pick up on different words, accents, and even unique speaking styles. This extensive training helps the system make intelligent guesses about what's being said, even when there's background noise or people talking over each other.
From Sound Waves to Sentences
So, how does it actually work? The process is a fascinating blend of sound analysis and language interpretation. First, the AI breaks down the audio into its smallest sound units, called phonemes. For example, the word “speech” is made up of four phonemes: /s/, /p/, /iː/, and /tʃ/.
Once the audio is broken down into these basic sounds, the system uses sophisticated algorithms to string them back together into words and sentences that make sense. This is where two key fields of AI come into play:
- Machine Learning (ML): The AI constantly learns from new data. By processing millions of hours of audio and their matching transcripts, it gets better and better at recognizing speech patterns and improving its accuracy over time.
- Natural Language Processing (NLP): This is the part that helps the AI understand language like a human. NLP gives the system context, allowing it to figure out grammar, sentence structure, and even the difference between words that sound the same, like "their," "there," and "they're."
The real breakthrough here is that the AI isn't just hearing sounds—it's learning to comprehend language. This ability to grasp context is what makes today’s audio-to-text AI so much more powerful than the clunky voice software of the past.
This technology has grown far beyond basic dictation. Journalists can now transcribe hours of interviews in just a few minutes, and companies can quickly analyze customer calls to find out what people really think. Audio-to-text AI is unlocking the massive amount of valuable information previously stuck inside audio and video files, turning spoken conversations into a practical, searchable resource.
How AI Learns to Understand Human Speech
Ever wondered how an audio to text AI actually works? It’s less like a computer memorizing a dictionary and more like teaching a child a new language. The process is all about listening, spotting patterns, and slowly piecing together how sounds become words, and how those words create meaning. It's a fascinating, step-by-step journey from raw sound to readable text.
It all starts the second your voice hits a microphone. The AI's first task is to take those analog sound waves and turn them into a digital format it can understand. This process, called digitization, is like taking thousands of tiny snapshots of the sound every single second, creating a super-detailed digital map of your speech.
This is the foundational step. It takes the messy, continuous flow of human conversation and turns it into structured data, giving the machine a permanent record it can actually analyze.
From Digital Signals to Phonetic Building Blocks
With the audio now in a digital format, the AI gets to work breaking it down into the smallest units of sound that differentiate one word from another. These are called phonemes. Think about the difference between "cat" and "bat"—it all comes down to a single phoneme, the initial /k/ versus the /b/ sound.
The AI meticulously analyzes the digital audio signal to pinpoint these distinct sounds. Imagine trying to write down every individual sound in a language you don't know—it's a tough job. The complexity skyrockets when you factor in different accents, speaking speeds, and background noise, all of which can dramatically alter how a phoneme sounds.
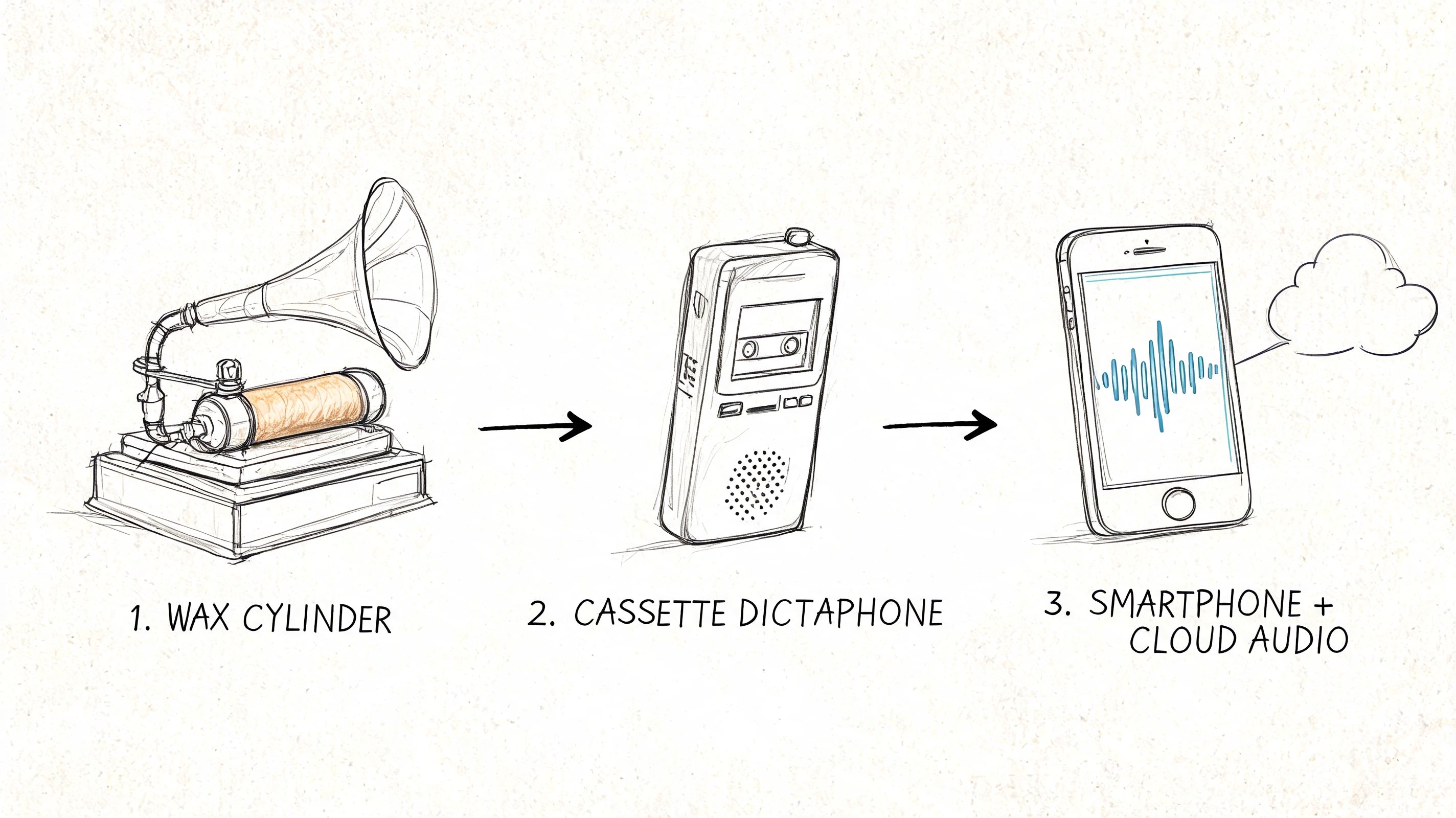
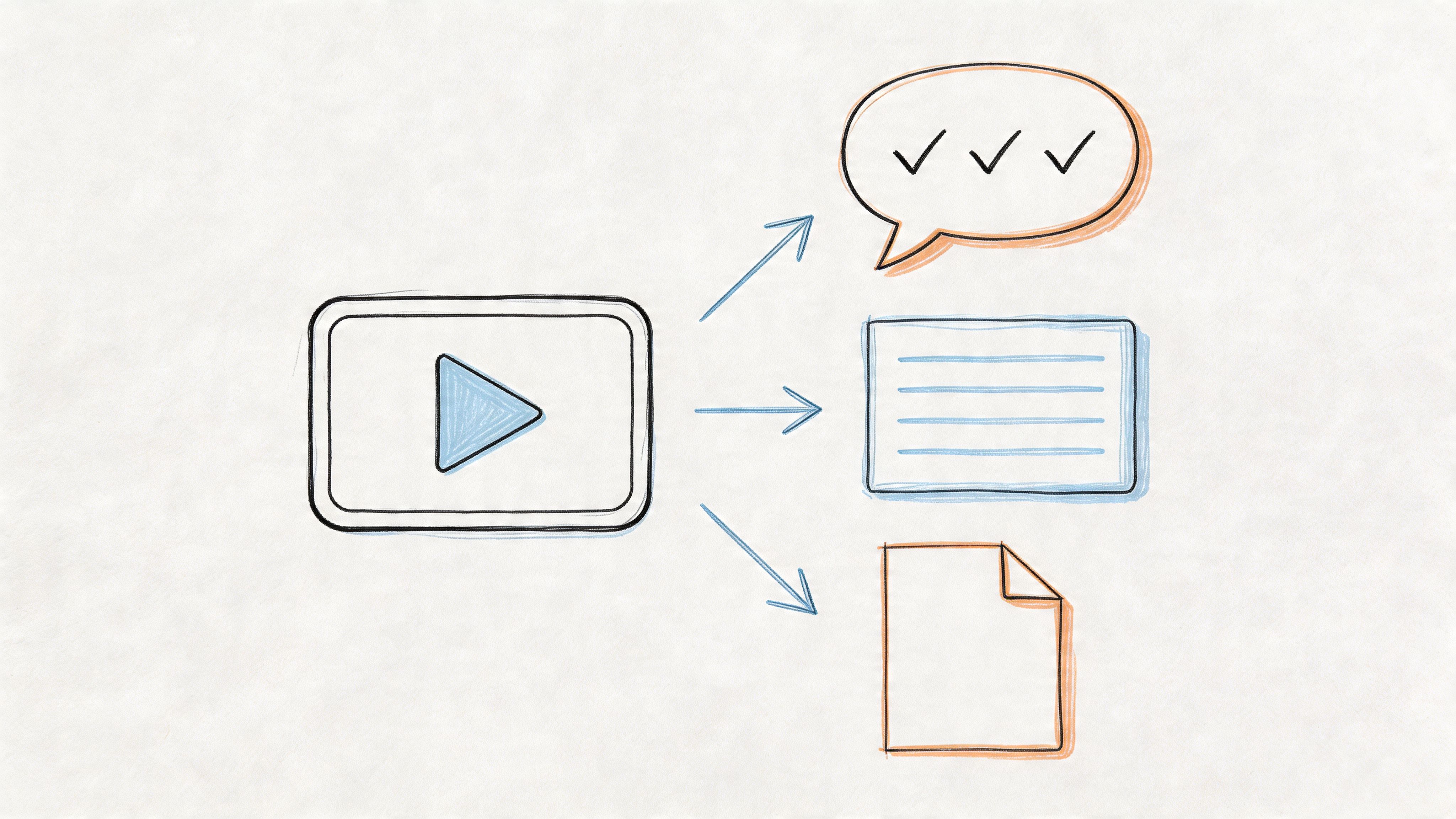
This visualization breaks down how raw audio is captured, processed, and ultimately turned into a clean transcript.
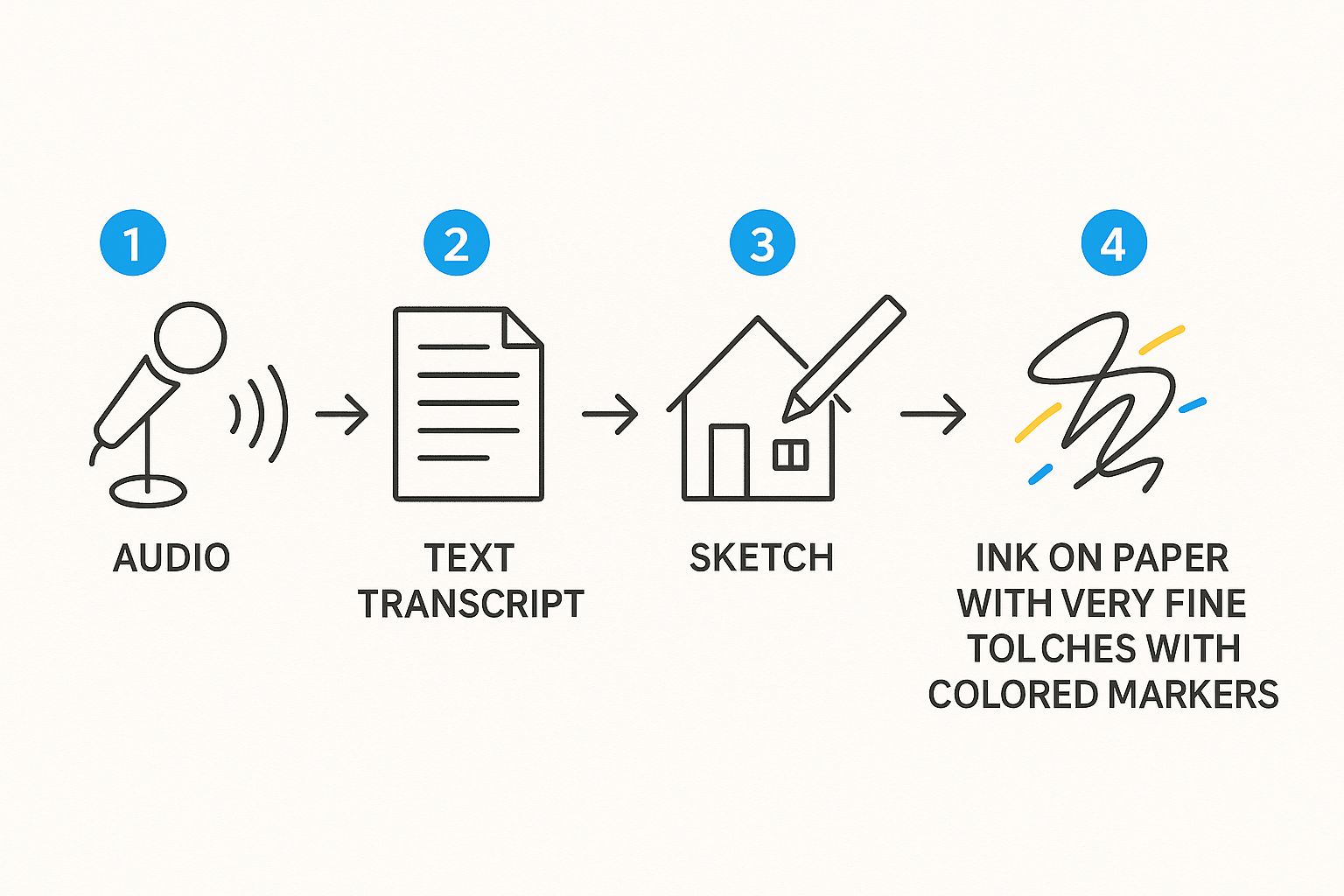
The image really shows the core of what audio-to-text AI does, making a highly technical process feel much more straightforward.
Assembling Meaning with Deep Learning
Just identifying phonemes isn't enough. The real magic happens next, when the AI uses sophisticated deep learning models to assemble these sounds into words, then phrases, and finally complete sentences. These models are often neural networks, designed to loosely mimic how our own brains process information.
These networks are trained on absolutely massive datasets—we're talking millions of hours of audio that have been manually transcribed and verified by humans. By churning through this enormous library, the AI starts to learn the subtle patterns of language.
- It Grasps Context: It learns that even though "write" and "right" sound the same, they mean different things based on the words around them.
- It Makes Educated Guesses: The AI gets good at predicting the next likely word. If it hears "turn on the…," it knows "light" is a far more probable word than "lion." This helps it fill in gaps and correct itself when the audio isn't perfect.
- It Gets Smarter Over Time: Every new piece of audio it analyzes is another learning opportunity. This continuous feedback loop helps the model get better at handling different accents, dialects, and speaking styles.
At the end of the day, it all comes down to the training data. The more diverse and comprehensive that data is—covering different languages, topics, and noisy environments—the more capable the AI becomes. It's a constant cycle of learning and getting better.
This sophisticated process is fueling some serious growth. The AI transcription market was valued at USD 4.5 billion in 2024 and is expected to rocket past USD 19.2 billion by 2034. With a market share of over 35.2%, North America is leading the charge, showing just how much businesses are relying on this tech to get more done. You can dig into the numbers yourself in this detailed market analysis about AI transcription.
Ultimately, the AI isn't just typing out words; it's learning the very structure of human communication.
What AI Transcription Actually Does for You in the Real World
Technical specs are one thing, but the real magic of an audio to text AI is how it solves everyday problems. It completely changes the game for how we handle spoken information, transforming hours of audio or video into something we can actually use—something that’s searchable, accessible, and ready for action. The benefits go way beyond just saving a little time; they touch everything from personal productivity to company-wide strategy.

The first and most obvious win is a huge productivity boost. If you've ever tried to transcribe audio by hand, you know it's a grind. A professional transcriptionist might spend four to six hours just to get through a single hour of audio. AI tools get the same job done in minutes, handing you back countless hours for work that actually matters.
This isn't a small change. It means teams can spend their brainpower on analyzing information and making decisions instead of just typing it all out. A journalist can get their story out faster. A researcher can sift through interview data in a fraction of the time. A student can get reliable notes from a lecture without having to scribble furiously the whole time.
Making Your Content Accessible to Everyone
Another massive benefit is how AI transcription opens doors for accessibility. Millions of people around the world live with some form of hearing loss, which can make audio and video content a major barrier. By providing accurate, automated captions and transcripts, AI transcription tears that barrier down.
This ensures everyone has a chance to engage with your content, no matter their hearing ability. It's also a huge help for non-native speakers who can follow along by reading, or for anyone trying to watch a video in a loud place where they can't hear the sound.
Generating instant captions and transcripts isn't just a cool feature—it's a step toward being more inclusive. It opens up communication and makes sure important information, from university lectures to public service announcements, is available to everybody.
Plus, offering a text version of your audio helps people who just learn better by reading. A transcript lets them go over the material at their own speed. Adding accurate timestamps is even better, as it helps people find specific moments in the recording. You can learn more about this in our guide to transcription with timecodes.
Tapping Into a Goldmine of Data
For businesses, maybe the most powerful benefit is the ability to finally make sense of all their audio data. Just think about how much spoken information a company creates every single day—customer support calls, sales pitches, webinars, team meetings. Most of that valuable intel is just sitting there, completely unsearchable and unused.
An audio to text AI flips that script. It turns all those spoken words into a searchable text database, creating some incredible opportunities for analysis.
For instance, a marketing team could:
- Gauge Customer Mood: Quickly search hundreds of support call transcripts for words like "frustrated," "confused," or "love it" to get a real pulse on customer sentiment.
- Pinpoint Product Feedback: Automatically find every time a specific feature is mentioned in user interviews, giving the product team direct feedback.
- Monitor the Competition: Get alerts whenever customers bring up a competitor on a sales call, uncovering important market trends.
This whole process turns messy, unstructured audio into clean, structured information you can actually analyze. It gives businesses a direct line to the voice of their customers, allowing them to make smart, data-driven decisions based on what people are actually saying. Turning conversations into strategy is a huge competitive edge in any field.
How Different Industries Use Audio to Text AI
The real magic of audio to text AI shines when you see it solving actual problems for real people. While the tech itself is complex, its uses are incredibly practical—saving time, cutting costs, and opening up new possibilities in all sorts of fields. From a busy hospital ward to a high-stakes courtroom, this technology is changing the way work gets done.

This isn't just a fleeting trend; it’s a fundamental shift in how we handle spoken information. You can see this shift reflected in the numbers. The global market for speech-to-text technology is booming, projected to hit around USD 4.42 billion in 2025. It’s expected to keep growing at a compound rate of 14.1% through 2030, largely driven by its adoption in critical areas like healthcare and customer service. Grand View Research has a great breakdown of this market's growth.
Let's dive into some specific examples of how this technology is making an impact. Below is a quick look at how different sectors are putting audio-to-text AI to work.
Audio to Text AI Applications by Industry
IndustryCommon ChallengeAI-Powered SolutionHealthcareTime-consuming and error-prone manual patient documentation.Real-time dictation of patient notes directly into electronic health records (EHRs).Media & EntertainmentSlow, expensive creation of captions, subtitles, and transcripts.Automated transcription of audio/video for accessibility, SEO, and global reach.LegalHigh costs and long turnaround times for transcribing depositions and court records.Fast, secure, and searchable transcripts of legal proceedings for quicker case prep.Customer ServiceDifficulty analyzing call logs to identify trends and improve agent performance.Transcription of customer calls for sentiment analysis, quality assurance, and training.EducationStudents with disabilities struggle to keep up with lectures; researchers spend hours transcribing interviews.Live lecture captioning and instant transcription of research interviews and focus groups.
As you can see, the applications are all about tackling a common bottleneck: turning spoken words into useful, actionable data. Now, let’s explore a few of these in more detail.
Speeding Up Patient Care in Healthcare
In any medical setting, documentation is absolutely critical but also a major time sink. Doctors and nurses spend a huge chunk of their day updating patient records, often after a long shift when they’re already exhausted. This can easily lead to burnout and simple mistakes. The core challenge is capturing detailed notes accurately without taking time and focus away from the patient.
This is where audio to text AI steps in as a game-changer. A doctor can simply dictate their notes during or right after a patient visit, and an AI system transcribes everything directly into the patient's electronic health record (EHR).
- Boosts Accuracy: The AI is trained to recognize complex medical terms, cutting down on the kinds of typos that can happen with manual entry.
- Frees Up Time: Clinicians can finish their documentation in a fraction of the time, letting them either see more patients or just spend more quality time with the ones they have.
- Improves Patient Focus: Instead of staring at a screen and typing, a doctor can maintain eye contact and give the patient their full attention.
Ultimately, this isn't just about making life easier for the staff. It directly contributes to better patient outcomes by ensuring every record is detailed, accurate, and immediately available.
Reshaping Media and Content Creation
If you're a podcaster, YouTuber, or work for a media company, your goal is to create content that’s both engaging and accessible. One of the biggest hurdles has always been the slow, expensive process of creating captions, subtitles, and written transcripts. This work is vital for reaching a global audience and for making content available to people with hearing impairments.
Audio to text AI completely automates this workflow. It can generate an accurate transcript from an audio or video file in minutes, not hours.
By instantly creating captions and transcripts, content creators can make their work globally accessible and searchable. This simple step broadens their audience reach and significantly improves the user experience for everyone.
Think about it: a YouTuber can upload a new video and have accurate captions ready to go almost instantly. This immediately opens up their content to international viewers and anyone watching with the sound off. Podcasters can post full transcripts on their websites, which is great for accessibility and also a huge boost for SEO, as it makes their spoken content discoverable by search engines. If this sounds like something you need, our guide on how to transcribe a YouTube video is a great place to start.
Bringing a New Level of Precision to the Legal World
The legal profession lives and breathes on the spoken and written word, where every detail matters. Traditionally, transcribing depositions, court proceedings, and witness interviews required highly skilled court reporters. This process is not only expensive but also slow, and any delay or mistake can have serious consequences for a case.
AI-powered transcription offers a much faster and more affordable alternative. Law firms can securely upload audio recordings and get back a detailed, searchable transcript in minutes. The speed alone is a massive advantage.
- Quicker Case Prep: Legal teams can instantly review testimony, search for key phrases, and pinpoint critical information without waiting days for a human transcriptionist.
- Lower Costs: Automating the transcription process dramatically reduces the expense of documenting legal events.
- Smarter Documentation: Many AI tools can even identify different speakers, which makes it much easier to follow conversations in meetings or depositions with multiple people.
By taking over the heavy lifting of transcription, audio to text AI lets legal professionals focus their energy on what they do best: building a case, analyzing evidence, and advising their clients. It makes the entire legal process more efficient and effective.
A Closer Look at Whisper AI: The Gold Standard in Transcription
To really see what a top-tier audio to text AI can do, it’s best to look at a real-world leader. OpenAI's Whisper AI has become a benchmark in the field, not just for its impressive performance, but for how it has raised the bar for everyone else. It was a massive leap forward in making truly high-quality speech recognition available to all.
What makes Whisper so special? It all comes down to its training. The model learned from a massive and incredibly diverse dataset: 680,000 hours of audio pulled from the web, covering multiple languages and tasks. This colossal amount of data gave it an uncanny ability to understand a huge variety of accents, dialects, and even niche technical jargon.
This training also made it tough. Whisper can churn out accurate transcripts even when the audio is less than ideal—think background noise, people talking over each other, or a shoddy microphone. These are exactly the kinds of situations that cause other models to stumble.
The Power of Being Open-Source
Perhaps the most important decision OpenAI made with Whisper was to release it as an open-source model. This means that anyone—from developers and researchers to businesses—can access, use, and build on its technology without paying for an expensive license. This single move has kicked off a wave of innovation in the audio world.
Going open-source gives you a level of freedom and control that’s impossible with closed, proprietary systems. Developers can tweak the model for their specific needs or bake it directly into their own software.
Whisper's open-source nature has democratized access to world-class transcription. It gives everyone, from an indie podcaster to a global corporation, the power to build tools that were once out of reach for all but a few tech giants.
This accessibility has fueled a thriving ecosystem of tools and services built on Whisper’s foundation. We're seeing custom solutions pop up for specific industries, from medical dictation software that knows clinical terms to media tools built to subtitle foreign films. And with support for over 90 languages, it’s a genuinely global tool.
Real-World Skills and Market Impact
Beyond the impressive tech specs, Whisper AI delivers on practical features that fix everyday problems. Its multilingual transcription is a game-changer; you can feed it a file with multiple languages spoken, and it figures it out without you having to tell it anything. It also handles punctuation and capitalization with surprising accuracy, giving you text that needs far less editing.
The impact of models like Whisper is rippling out into related areas. Take AI Voice Generators, for example. This rapidly growing market, which focuses on turning text into natural-sounding speech, was valued at USD 3.58 billion in 2024 and is expected to soar to USD 36.43 billion by 2032. This trend, detailed in this AI voice generator market analysis, shows the booming demand for AI that can move fluidly between text and audio.
Whisper AI paints a very clear picture of what a modern audio to text AI is truly capable of. Its mix of accuracy, resilience, language support, and open-source philosophy has set a new standard for what we should all expect from transcription technology.
How to Get Started with Audio to Text AI
So, you're ready to put this technology to work? Good news: getting started with audio to text AI is easier than you might think. There are great options out there for every skill level and budget.
Whether you just need a quick transcript for a single meeting or you're looking for a heavy-duty solution for your entire company, there's a clear path forward. It all starts with figuring out what you actually need. Are you a student trying to convert a lecture recording, or a developer aiming to build transcription features directly into an app? The right tool always depends on the job at hand.
Choosing Your Path
Generally, there are three main ways you can tap into audio to text AI technology. Each has its own pros and cons.
- User-Friendly Online Tools: This is the simplest and most direct route. Dozens of websites and apps offer a straightforward "upload and transcribe" service. You just give it your audio or video file, and the platform spits out a finished transcript, often in minutes. These are perfect for individuals and small teams who need fast, occasional transcriptions without any technical fuss.
- Powerful APIs for Integration: For developers and businesses, an Application Programming Interface (API) is the way to go. APIs let you plug transcription capabilities directly into your existing software. Imagine automatically transcribing customer support calls right inside your CRM or adding instant captioning to your video platform. It requires some coding know-how, but the flexibility is unbeatable.
- Open-Source Models: For anyone wanting total control, open-source models like Whisper AI are the ultimate playground. You can host the model on your own servers, fine-tune it to recognize specific industry jargon, and guarantee your data never leaves your sight. This path offers the most power, but it also demands serious technical expertise to set up and manage.
Key Factors to Consider Before You Start
Making the right choice really just comes down to weighing a few key factors. Before you sign up for a service or kick off a project, run through this quick checklist.
- Accuracy Needs: How perfect does the transcript need to be? For casual notes, 90% accuracy might be totally fine. But for legal or medical records, you'll want a state-of-the-art model that can deliver 95% or higher accuracy.
- Budget Constraints: Options run the gamut from free trials and pay-as-you-go services to pricey enterprise licenses. Figure out your budget first to narrow the field. Open-source models might be free, but don't forget you'll have to pay for the server power to run them.
- Language and Format Support: Does the tool handle the languages and dialects you need? Also, check which file formats it can work with. If you record a lot of voice memos as M4A files, you need a tool that can process them. Our guide on how to transcribe M4A to text has more on that.
- Data Privacy Policies: This is a big one. If you're transcribing anything sensitive, this is non-negotiable.
Always review a provider's privacy policy. Look for clear commitments to data encryption and find out if your files will be stored long-term or used for training their AI. Your data's security should always be a top priority.
By thinking through these points, you can confidently pick the right audio to text AI solution for you. It's the best way to make sure you get the accuracy, features, and security you need to turn spoken words into a truly valuable asset.
Got Questions About Audio to Text AI? We’ve Got Answers.
As you get more familiar with this technology, a few common questions tend to pop up. Let's tackle some of the big ones so you can feel confident choosing and using the right tools.
How Accurate Is This Stuff, Really?
Modern audio-to-text AI can be incredibly accurate, with the best tools hitting over 95% accuracy under the right conditions. But that percentage isn't set in stone; it really depends on the quality of your audio.
Think of it this way: a crystal-clear recording of one person speaking directly into a good microphone will give you a near-perfect transcript. But if you throw in a lot of background noise, thick accents, or a bunch of people talking over each other, the accuracy will naturally dip. The microphone quality itself is a huge factor, too.
The best systems are constantly learning from new data, which means they’re always getting better at handling tricky audio. The smartest move is to test any tool with a real sample of your own audio to see how it holds up for your specific needs.
Is My Data Safe with These AI Services?
That's a great question, especially when you're transcribing sensitive meetings or private conversations. Reputable AI transcription services understand this and build their platforms with security as a top priority.
When you're shopping around, look for key security features. End-to-end encryption is a must-have—it keeps your data protected while it's being uploaded and while it's stored. Also, check for compliance with standards like GDPR or CCPA, which shows they take data privacy seriously.
A trustworthy provider will always have a clear privacy policy. Make sure it explicitly states that your data won't be used to train their AI models unless you give them permission.
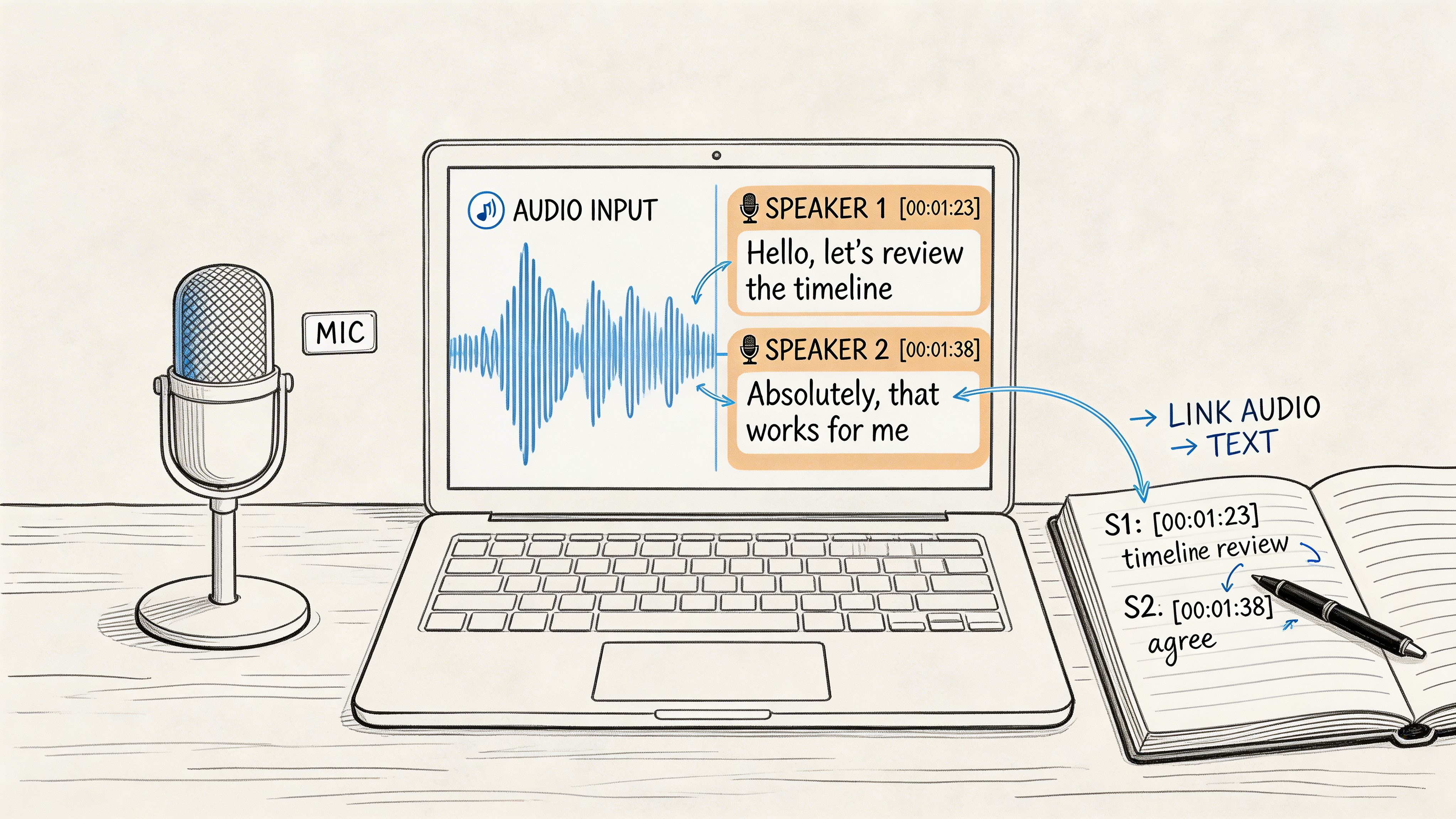
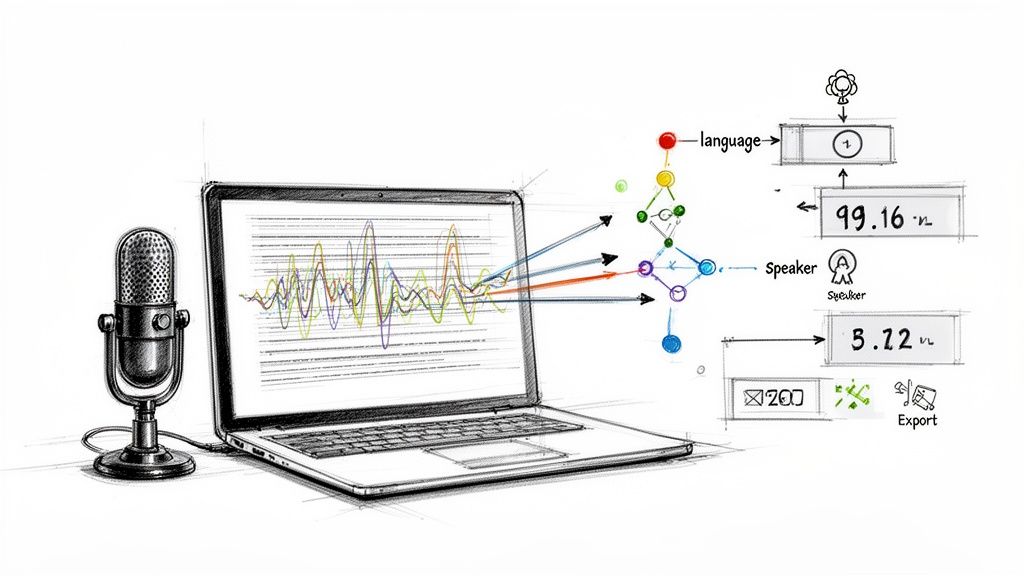
Can the AI Tell Who's Talking?
Yes, absolutely! Many of the more advanced platforms have a feature called speaker diarization, which is just a technical way of saying they can tell different speakers apart.
It works by analyzing the unique qualities of each voice—things like pitch, tone, and cadence—to create a sort of vocal fingerprint. The AI then uses these fingerprints to label each part of the conversation, showing you exactly who said what. This is a game-changer for transcribing interviews, meetings, or podcasts, making the final text infinitely easier to follow.
Ready to turn your audio and video into accurate, organized text? Whisper AI offers top-tier transcription, summarization, and speaker identification in over 92 languages. Try Whisper AI for free and see the difference for yourself.