A Practical Guide to Modern Audio to Text Technology
Ever tried to find one specific comment in a recording of an hour-long meeting? Or maybe pull a single powerful quote from a long interview? It’s a classic needle-in-a-haystack problem. This is exactly where audio to text technology steps in, acting like a blazingly fast digital stenographer that turns your spoken words into text you can edit, search, and share.
This guide is based on our direct experience working with transcription tools and helping users get the best results. We'll walk you through exactly what this technology is, how it works, and how you can use it to save time and unlock new possibilities.
What Exactly Is Audio to Text Conversion?
At its heart, audio to text conversion is the process of translating spoken language from an audio file into written words. Think of it as building a bridge from the audible world to the digital, readable one. Instead of having someone manually type out every word from a recording—a tedious and time-consuming job—this technology automates the whole thing.
And we're not just talking about simple dictation anymore. Modern audio to text systems, fueled by sophisticated artificial intelligence, can navigate complex conversations with impressive accuracy. The technology has grown far beyond the simple voice commands we use on our smartphones.
How Does Unlocking Spoken Data Help You?
The real magic of converting audio to text is how it unlocks all the valuable information trapped inside voice recordings. Spoken words are temporary and nearly impossible to analyze at scale. But once they're converted to text, they become a powerful asset.
Suddenly, you can search hours of conversation with a simple keyword. This shift from sound to structured data opens up a world of possibilities and is a genuine game-changer for professionals across almost every industry.
- Searchability: Need to find a specific topic, name, or decision? You can pinpoint it in massive audio files instantly without having to listen to the whole thing all over again.
- Accessibility: Transcripts make your audio and video content accessible to people who are deaf or hard of hearing, which helps you reach a much wider audience.
- Repurposing Content: That one podcast episode can be effortlessly spun into a dozen blog posts, countless social media updates, and all sorts of marketing materials.
- Analysis and Insights: Businesses can finally analyze customer service calls or focus group recordings to spot trends, gauge sentiment, and pull out critical feedback.
In short, audio to text technology makes your spoken content as flexible and useful as any written document. It turns a one-dimensional audio file into a resource you can use in countless ways.
This core capability paves the way for a huge range of applications, from automatically creating meeting summaries to generating subtitles for videos. By making voice content readable by machines, we open up new avenues for automation and a much deeper level of understanding. The process has gone from a niche, labor-intensive service to a tool anyone can use to work smarter and get more done.
The Long Road to Machines That Listen
It’s easy to take for granted how effortlessly a machine can turn spoken words into text today. But behind that simple function is a fascinating and complex story that stretches back decades—a journey filled with ambitious ideas, tough technological roadblocks, and one breakthrough after another.
This story didn't start in the cloud or on a smartphone. It began with massive, room-sized machines long before personal computers were even a concept. Researchers back then were already trying to crack the code of human speech.
From Simple Digits to Full Sentences
The earliest roots of transcription technology go all the way back to the middle of the 20th century. One of the first systems on record was Bell Laboratories' 'Audrey' in 1952. This wasn't a sleek app; it was a huge piece of hardware that could recognize spoken digits from a single voice, hitting about 90% accuracy on a good day. A decade later, IBM's 'Shoebox' came along, capable of understanding 16 English words and even doing basic math.
Things really started picking up in the 1970s with Carnegie Mellon University's 'Harpy' project. Harpy expanded its vocabulary to over 1,000 words and could understand complete sentences. By the 1990s, speech recognition finally started hitting the mainstream with consumer products like Dragon Dictate, which brought the technology into offices and homes for the first time. If you want to dive deeper into these early milestones, you can explore a brief history of speech-to-text technology here.
Of course, these early systems were impressive for their time but had some serious limitations. They typically struggled with:
- Tiny Vocabularies: Most could only recognize a very small, pre-programmed set of words.
- Speaker Dependence: You had to spend ages training them on your specific voice, and they were useless for anyone else.
- Perfect Conditions: Any background noise or slight change in how someone spoke could throw the whole system off.
The fundamental problem for early engineers was translating the messy, analog flow of sound waves into the clean, digital language that computers understand. Their first attempts were like building a visual lookup table for sounds—a very rigid approach.
A Smarter Approach: Thinking in Probabilities
The real game-changer came when researchers stopped trying to find a perfect match for every sound. Instead of trying to line up a spoken word with a flawless, pre-recorded template, they started using statistical models. This was a completely different way of thinking about the problem.
This new wave of technology was built on something called Hidden Markov Models (HMMs). An HMM-based system didn't need a perfect audio match. Instead, it calculated the probability that a certain string of sounds represented a particular word. Think about how you decipher a muffled sentence in a loud room—you use context and what's most likely being said. HMMs gave computers a similar, much more flexible skill.
This statistical method made transcription systems way more powerful. They could finally handle different accents, speaking speeds, and pronunciations without failing. It was this breakthrough that allowed vocabularies to jump from just a few hundred words to tens of thousands, making things like digital dictation practical for the first time. The focus had shifted from rigid rules to intelligent guesswork.
The Modern Age of Neural Networks
The most recent—and by far the most powerful—leap forward has been the move to deep learning and neural networks. If the old statistical models taught computers to make educated guesses, neural networks teach them to learn and spot patterns in a way that’s loosely inspired by the human brain.
Today's AI audio-to-text tools are trained on mind-boggling amounts of data—thousands upon thousands of hours of real-world speech from every corner of the internet. This massive training library allows the models to absorb all the subtle details of human language, from regional accents and dialects to slang and industry-specific terms.
This is why the tools we use now are so incredibly accurate. They aren't just matching sounds anymore; they're understanding context, grammar, and the natural flow of conversation. The path from 'Audrey' recognizing a few digits to an AI like OpenAI’s Whisper transcribing complex meetings is a testament to decades of relentless innovation. Each step built on the last, turning a sci-fi dream into an everyday tool.
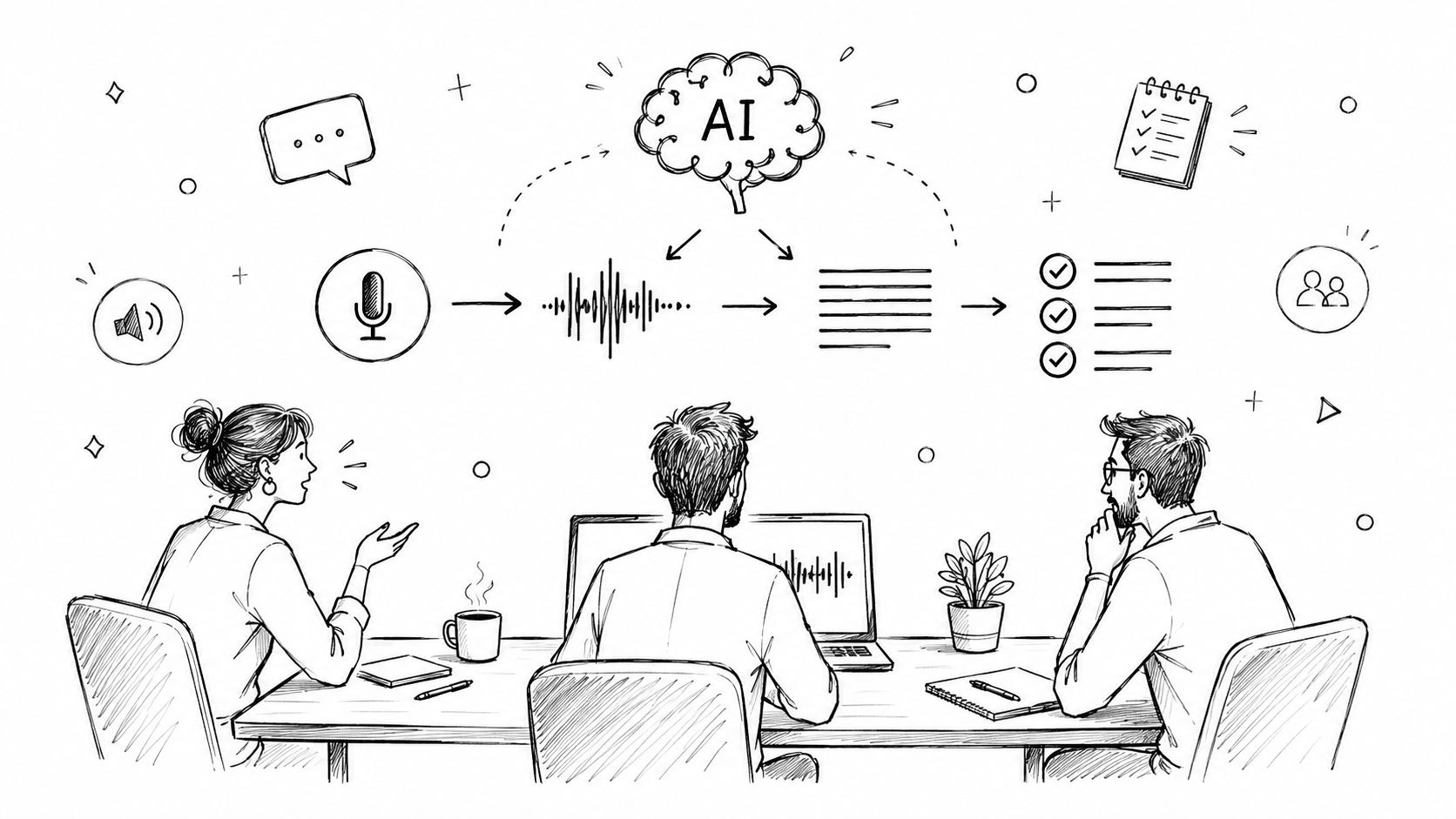
How Modern Transcription AI Actually Works
Ever wonder how your phone can instantly turn your spoken words into a text message? It’s not magic, but it’s close. Think of the AI as a dedicated student learning to understand human speech. It doesn't just memorize a dictionary; it learns the fundamental sounds and the intricate rules of language, a process that happens in two critical stages.
First up is the Acoustic Model. This is the AI's ear. Its one job is to listen to the raw audio—a messy jumble of sound waves—and chop it up into the smallest units of sound, called phonemes. In English, we have about 44 of these basic sounds, like "k," "sh," and "ah," which are the building blocks for every word we say.
To get good at this, the acoustic model is trained on thousands of hours of speech from all kinds of people. This teaches it to identify those phonemes correctly, no matter the accent, pitch, or speed of the speaker. It’s essentially building a universal map between the sounds it hears and the phonemes they represent.
From Sounds to Sentences
Once the acoustic model has a string of phonemes, the Language Model steps in. This is the AI's brain. It plays the role of a grammar guru and context detective, figuring out how to group those individual sounds into real words and sensible sentences.
Let's say the acoustic model picks up the phonemes for "let's," "eat," and "grandma." The language model, having analyzed billions of sentences from books and websites, knows that "Let's eat, Grandma!" is a much, much more likely phrase than "Let's eat Grandma." It's all about probability—predicting the most logical sequence of words based on what it's learned.
This tag-team of an expert listener (acoustic model) and a grammar whiz (language model) is what makes it possible for AI to convert spoken audio into accurate text. In the latest systems, these two components are often woven together into a single, powerful neural network. You can dive deeper into how this works in our guide on using AI for audio to text transcription.
The real game-changer was moving away from rigid, rule-based systems to ones that think in probabilities. Instead of hunting for a perfect sound match, modern AI calculates the most likely word or phrase, which makes it far more adaptable and accurate in the real world.
The Evolution from HMM to Deep Learning
The path to today’s incredibly accurate systems was a long one. A major breakthrough came in the 1980s and 90s with the adoption of Hidden Markov Models (HMMs). This statistical approach was a giant leap forward, allowing systems to estimate the probability of sound sequences. Tools like Carnegie Mellon’s SPHINX-I achieved speaker independence for the first time, while Dragon NaturallySpeaking brought continuous speech recognition into people's homes.
But as good as HMMs were, today’s best transcription tools are built on something even more sophisticated: deep learning neural networks. These networks are loosely inspired by the human brain and can process information with a level of nuance and context that was previously out of reach.
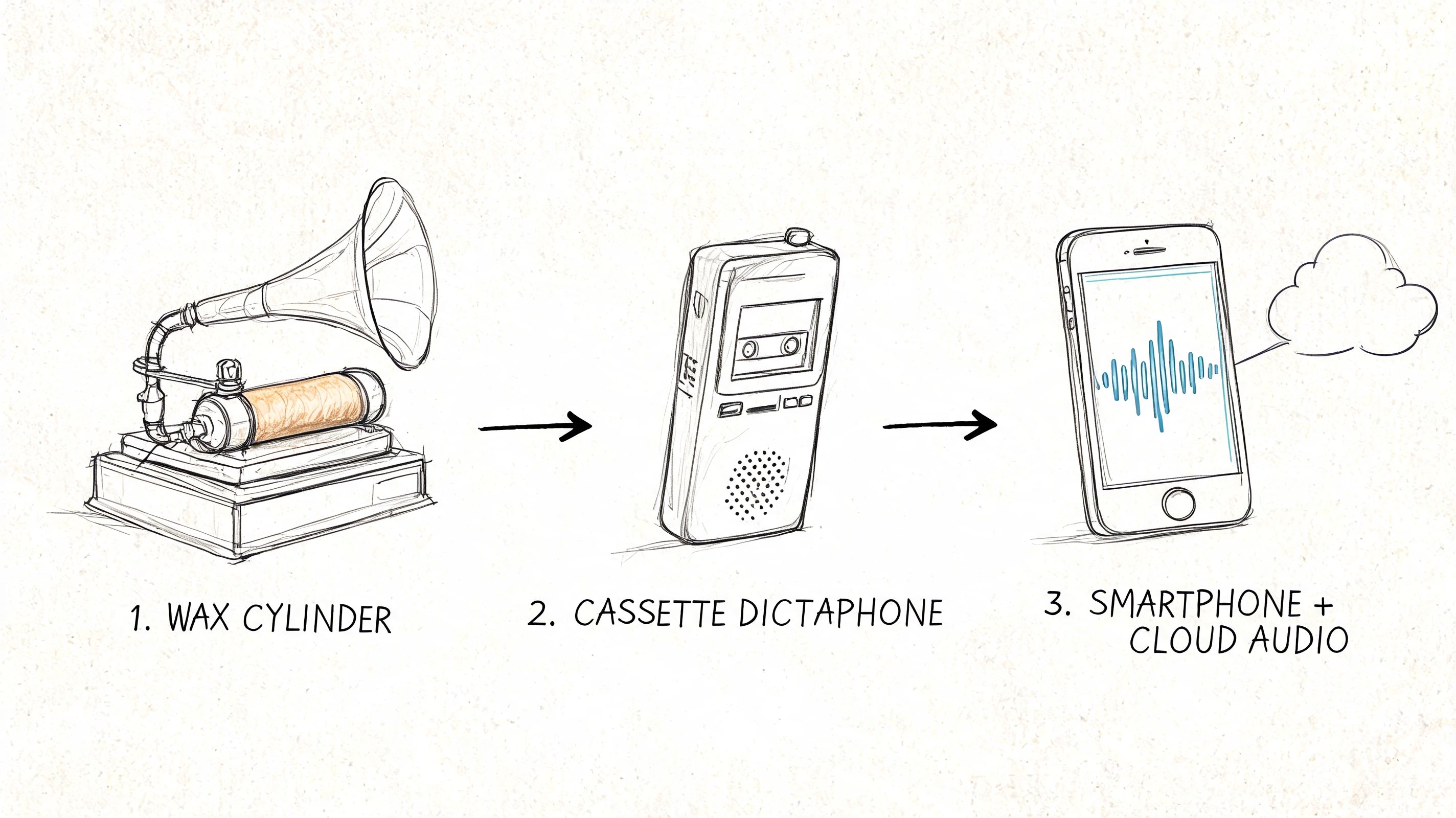
This infographic gives you a bird's-eye view of how speech recognition tech has evolved.
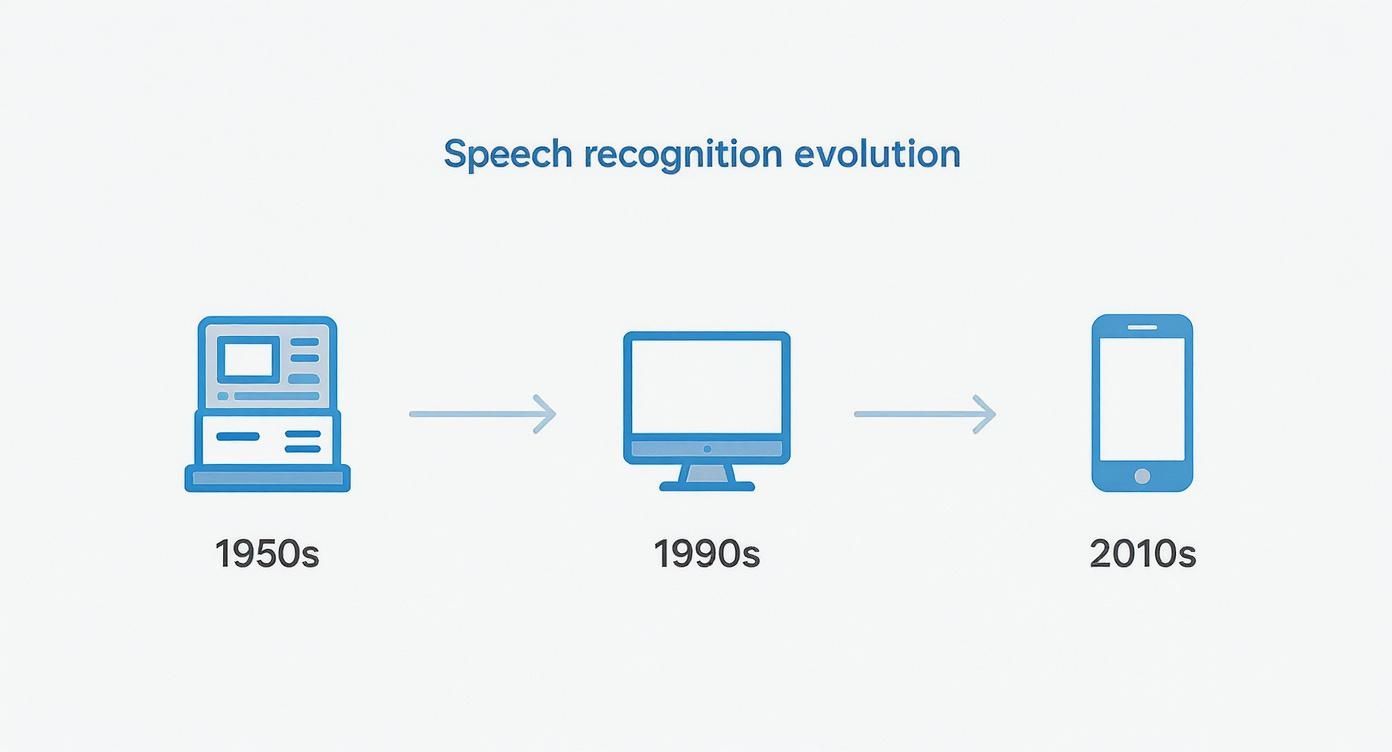
You can clearly see the journey from massive mainframes in the 1950s to the powerful software that now lives on our smartphones.
Why Massive Datasets Are the Secret Sauce
The stunning accuracy of models like OpenAI's Whisper isn't just about clever algorithms. It’s fueled by the absolutely massive amount of data they learn from. These models are trained on immense datasets, often containing hundreds of thousands of hours of audio scraped from the internet.
This training data is incredibly diverse, covering a huge range of:
- Languages and Dialects: By listening to speakers from all over the world, the AI gets remarkably good at understanding different accents.
- Topics and Jargon: The model learns everything from medical terminology and legal phrases to everyday slang.
- Acoustic Environments: The data includes audio recorded in noisy cafes, echoey halls, and over spotty phone connections, teaching the AI to filter out the junk and focus on the speech.
This is what gives modern AI its superpower: the ability to handle messy, real-world audio. It can transcribe a podcast with overlapping guests, a conference call with background noise, or a lecture from the back of the room with an accuracy that was pure science fiction just a decade ago. It learns context, predicts what’s coming next, and makes an educated guess on unclear sounds, bringing it closer than ever to human-level performance.
Practical Uses for Audio to Text in Your Work
The technology behind audio to text is impressive, but where it truly shines is in its real-world impact. This isn't just about clever algorithms; it's a practical tool that solves genuine problems, frees up thousands of hours, and opens up new possibilities in almost every field imaginable.
From fast-paced newsrooms to meticulous research labs, professionals are using transcription to work smarter, not harder. The core idea is brilliantly simple: it takes spoken words—a format that’s temporary and hard to organize—and turns them into structured, searchable data. That one shift unlocks a level of efficiency and insight that was once completely out of reach.
How Journalists and Media Creators Save Time
For any journalist, interviews are the foundation of their stories. Traditionally, this meant spending hours chained to a desk, manually typing every single word from a recording. It was a painfully slow and tedious process that created a huge bottleneck in getting a story out.
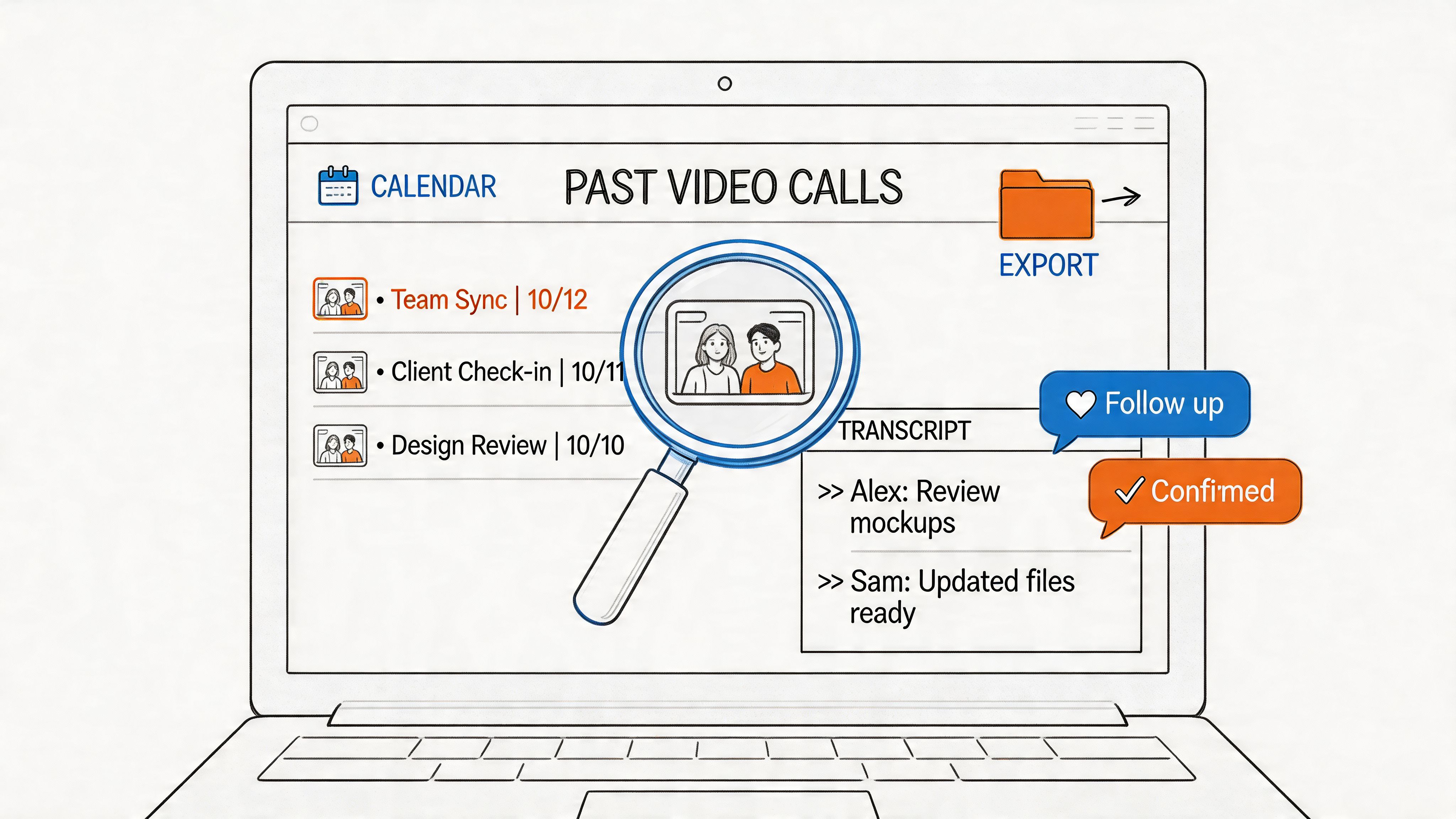
Today, AI-powered transcription tools completely flip that script. A reporter can finish a one-hour interview and have a full, accurate transcript ready to go in minutes. When you're up against a tight deadline, that speed is everything.
- Finding Key Quotes: Forget scrubbing back and forth through an audio file. Now, a quick keyword search instantly pulls up the most powerful quotes.
- Ensuring Accuracy: A written transcript serves as a definitive record, making it easy to double-check that every quote is captured perfectly.
- Streamlining Collaboration: Editors and fact-checkers can jump into the text-based interview right away, speeding up the entire editorial workflow.
This same advantage extends to podcasters, YouTubers, and other content creators. Many are now searching through video content using AI-generated transcripts to pinpoint specific moments in their own work. It also gives them an easy way to repurpose a single podcast or video into dozens of other assets, like blog posts, social media clips, and detailed show notes, squeezing every drop of value from their content.
How Transcription Enhances Accessibility and Education
In education, audio to text technology is a massive step forward for inclusivity. For students who are deaf or hard of hearing, getting transcripts of lectures isn't just a nice-to-have—it's absolutely essential for them to have the same access to information as their peers.
Educators can now automatically generate transcripts for their video lessons and audio materials. This ensures that every student can follow along, review complex ideas at their own pace, and easily search for specific topics when studying. It’s about leveling the playing field and making learning more accessible for everyone.
By converting spoken lessons into written text, educators can create a more flexible and inclusive learning environment where every student has the resources they need to succeed.
This also helps students who just happen to learn better by reading. Having a text version of a lecture lets them highlight important concepts, take more effective notes, and engage with the material in a way that truly clicks for them.
How Businesses and Healthcare Gain Efficiency
Think about how much valuable information is trapped inside phone calls in the business world. Customer service conversations, sales pitches, and user feedback sessions are all goldmines of insight. Listening back to all of them manually is impossible, but AI transcription makes it scalable.
By transcribing these conversations, companies can:
- Identify Customer Pain Points: Quickly spot recurring issues that people are calling about.
- Monitor Quality Assurance: Check if support agents are providing great service and sticking to key guidelines.
- Uncover Market Trends: Hear firsthand about the new features or products that customers are asking for.
It's a similar story in healthcare, where transcription helps doctors and nurses reclaim their time. Instead of spending hours typing up detailed notes after every appointment, a doctor can simply dictate their observations. An AI handles the transcription, creating an accurate medical record and freeing up the doctor to focus on what matters most: patient care.
The global adoption of this technology has exploded, largely thanks to smart devices and cloud-based AI. By the 2010s, assistants like Siri and Alexa had become household names, all built on deep learning models trained on enormous datasets. This boom fueled a global speech and voice recognition market valued at over $10 billion by 2020, with projections showing 17%-20% annual growth. This demand is largely powered by critical needs in healthcare, customer service, and the automotive industry.
Choosing the Right Audio to Text Tool for You
Trying to find the right way to turn your audio into text can feel like a maze. There are so many tools out there, and they all claim to be the best. But here’s the secret: the “best” tool is simply the one that fits your specific job.
To cut through the noise, let’s break down the three main choices you have: dedicated AI software, free built-in tools, and old-school human transcription services. Each one has a completely different set of strengths when it comes to accuracy, speed, cost, and even security. After all, transcribing a quick voice memo is a world away from creating a perfect transcript for a legal deposition.
Dedicated AI Transcription Software
This is where the real power lies. We're talking about specialized platforms, like services running on OpenAI's Whisper model, that are purpose-built for serious transcription work. Think of them as the heavy machinery of the audio-to-text world. They’re designed to chew through messy, real-world audio—like a team meeting with people talking over each other, an interview recorded in a noisy café, or a university lecture packed with technical jargon.
What makes them stand out?
- Serious Accuracy: Top-tier AI models can hit 95% accuracy or even higher, making them dependable enough for almost any professional task.
- Blazing Speed: Your audio files are typically turned into text in a matter of minutes. It’s a game-changer compared to waiting days for a human to do it.
- Smart Features: Many of these tools don't just transcribe. They can also identify who is speaking (diarization), add automatic timestamps, and even generate a summary of the whole conversation.
Yes, they usually have a price tag, but it’s a fraction of what you’d pay for a human transcriber, making the investment a no-brainer for businesses, researchers, and content creators.
Free Built-In Features
You’re already familiar with these, even if you don't think about it. It’s the little microphone icon on your phone’s keyboard or the dictation feature built into your computer. They are masters of convenience for quick, in-the-moment tasks.
These freebies are perfect for things like:
- Firing off a text message while you’re driving.
- Capturing a random thought or a shopping list item.
- Doing a quick voice search without typing.
But their limits show up fast when you ask for more. They tend to stumble over longer recordings, get confused by multiple speakers, and give up when there's background noise. For a closer look at what they can (and can't) do, check out our guide on the best free audio-to-text converters.
Free tools are fantastic for convenience and immediate needs. But for anything requiring high accuracy, longer durations, or professional output, a dedicated solution is almost always the better choice.
Traditional Human Transcription
Before AI took center stage, this was the only way. A real person would sit down with headphones, listen to your audio, and meticulously type out every single word. This human touch can produce incredibly accurate results, especially with really tough audio—think thick accents, terrible recording quality, or people constantly interrupting each other.
That precision, however, comes with major trade-offs. Human transcription is easily the most expensive and slowest option available. Getting your text back can take hours, if not days. It also introduces a layer of security risk, as you’re handing your private audio files over to a stranger. While it still has a place in highly sensitive legal or medical fields where 100% accuracy is an absolute must, modern AI software is now the more practical, balanced choice for just about everyone else.
Audio to Text Methods Compared
To make the decision even clearer, let's put these three approaches side-by-side. Seeing the pros and cons in one place can help you instantly spot which method aligns with your priorities, whether you're focused on budget, speed, or flawless accuracy.
Ultimately, the table tells the story. For the vast majority of modern needs—from business to content creation—dedicated AI software hits the sweet spot, delivering professional-grade results without the high cost or long wait times of traditional methods.
How to Get the Most Accurate Transcripts

Even the most sophisticated audio to text AI is only as good as the audio it’s given. It's a classic "garbage in, garbage out" scenario. Think of it like a chef—give them fresh, high-quality ingredients, and you’ll get a great meal. The same principle applies here: great audio in means a great transcript out.
The good news is you don’t need a professional recording studio to get fantastic results. Just a few simple tweaks to how you capture your audio can dramatically boost the accuracy of any transcription tool, making sure you get a clean, reliable text file every single time.
Set the Stage for Clear Audio
The bedrock of an accurate transcript is a clean recording. This really just means cutting out anything that could confuse the AI. Your main goal is to make the voices as clear and distinct as possible.
Before you even think about hitting record, focus on these key areas:
- Reduce Background Noise: Find the quietest space you can. Little things you might tune out, like an air conditioner, a humming refrigerator, or distant traffic, can really muddle the audio for an AI.
- Use a Decent Microphone: Sure, your laptop or phone's built-in mic will work in a pinch, but an external USB microphone is a small investment that pays huge dividends in clarity. Placing it closer to whoever is speaking makes their voice the star of the show.
- Avoid Cross-Talk: When multiple people are speaking, try to get them to talk one at a time. Overlapping conversations are one of the biggest hurdles for transcription AI, which struggles to untangle the intertwined audio.
Think of the AI's acoustic model as a listener in a crowded room. The quieter the room and the clearer each person speaks, the easier it is for that listener to follow the conversation accurately.
Post-Transcription Polish Is Key
Once your audio to text tool has done the heavy lifting, a quick final review is what separates a good transcript from a great one. AI is incredibly accurate these days, often hitting above 95%, but it can still stumble on the finer details that require human context.
Specifically, you should always give the transcript a quick once-over, looking for:
- Proper Nouns: AI can get creative when spelling unique names of people, companies, or specific places.
- Industry Jargon: Specialized terminology or acronyms might get misinterpreted if they weren't common in the AI's training data.
- Homophones: Words that sound the same but have different meanings (like "their," "there," and "they're") can sometimes get mixed up.
This final check is what transforms a very good transcript into a perfect one. For a more detailed walkthrough, you can learn more about how to transcribe audio files effectively in our complete guide. By combining smart recording habits with a quick proofread, you'll get a final text that's polished, professional, and ready for whatever you need it for.
Frequently Asked Questions About Audio to Text
As you start exploring how to turn audio into text, a few questions always pop up. It's only natural to wonder about things like accuracy, how the AI handles different speakers, and whether your files are safe. Getting these answers is crucial for picking the right tool and feeling good about using it.
Let's dig into the questions we hear most often.
How Accurate is AI Transcription, Really?
This is usually the first thing people ask, and the answer is that it's gotten really good, but it’s not magic. The quality of your audio is the single biggest factor. If you give the AI a clean recording—one person speaking clearly into a decent microphone with no background noise—you can expect incredible results. Top models like OpenAI's Whisper can hit accuracy rates over 95%.
But real life is messy. Accuracy can take a hit when you're dealing with:
- Loud background chatter or music
- Thick, unfamiliar accents
- People talking over each other
- A fuzzy or distant recording
Even the best AI isn't perfect, which is why a quick human review is always a good idea, especially for anything important.
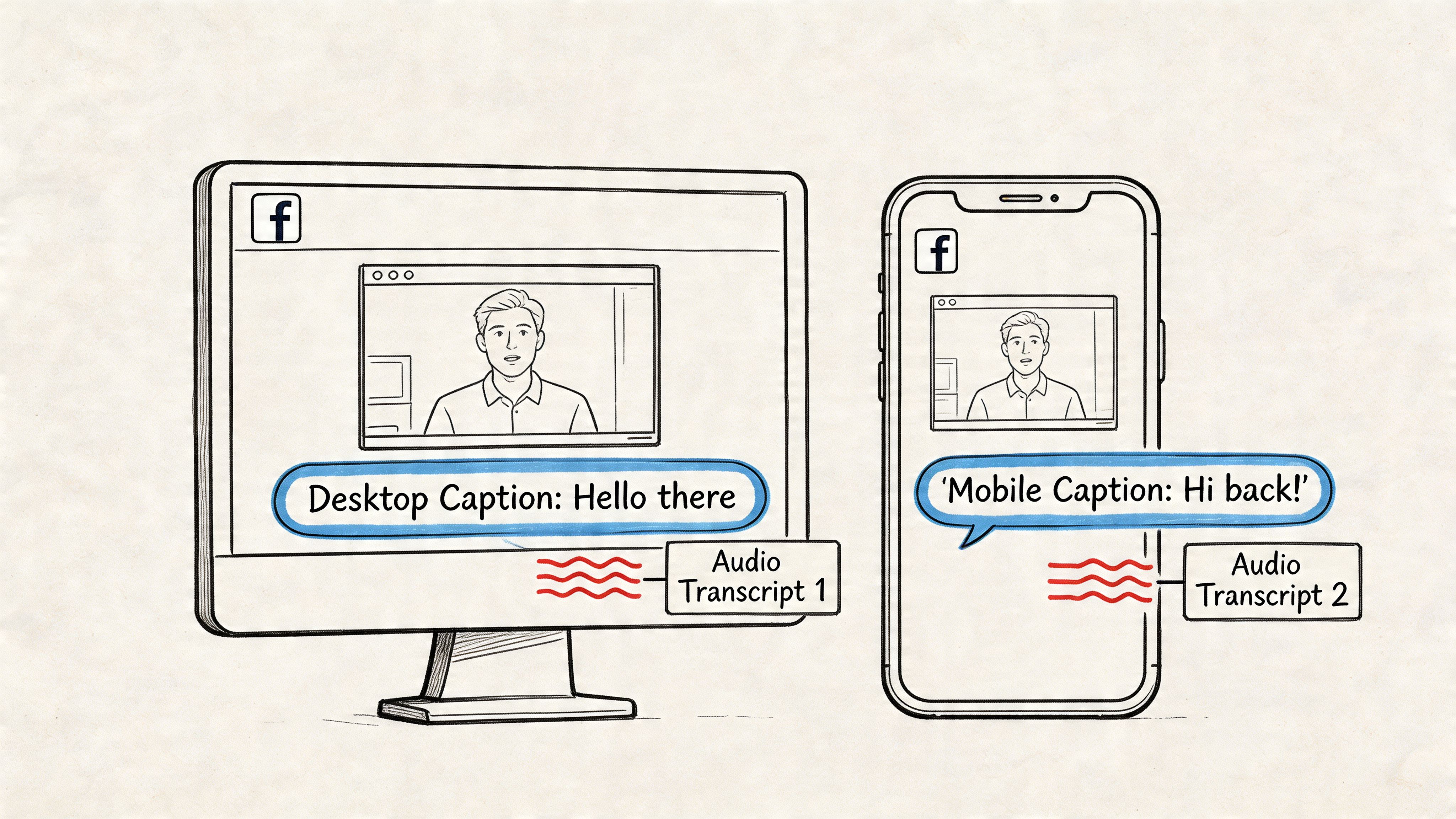
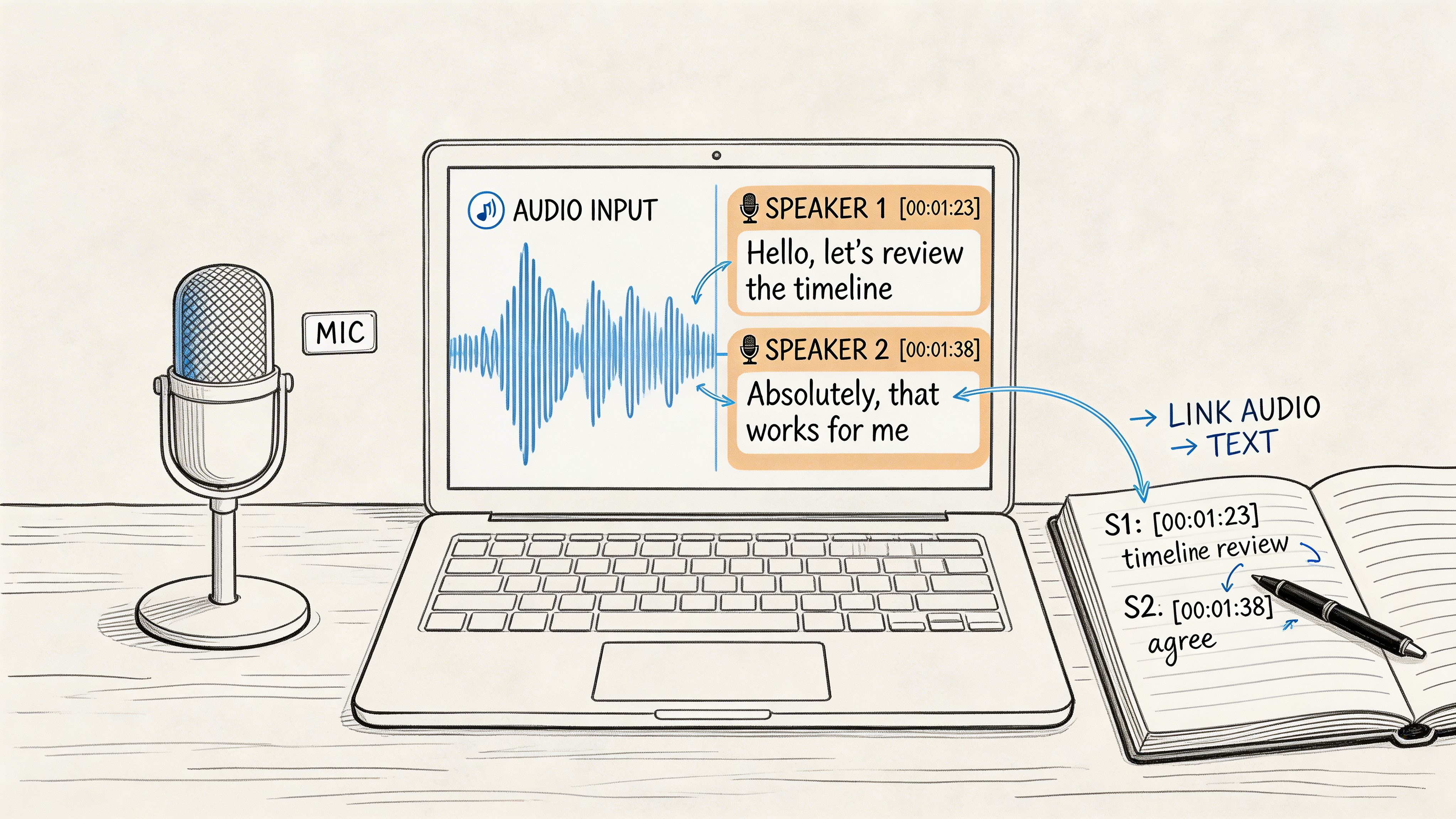
Can the AI Figure Out Who's Talking?
Yes, and this is an absolute game-changer for anyone transcribing interviews, meetings, or podcasts. This clever feature is called speaker diarization.
Think of it as the AI listening to a conversation and being able to tell one voice from another. Instead of spitting out a giant, confusing block of text, a tool with speaker diarization will neatly label the dialogue. You’ll see "Speaker 1," "Speaker 2," and so on, making it instantly clear who said what. It turns a chaotic conversation into a well-organized script.
Speaker diarization is what separates a decent transcript from a great one. It saves you the headache of manually sorting through a conversation and trying to remember who was speaking.
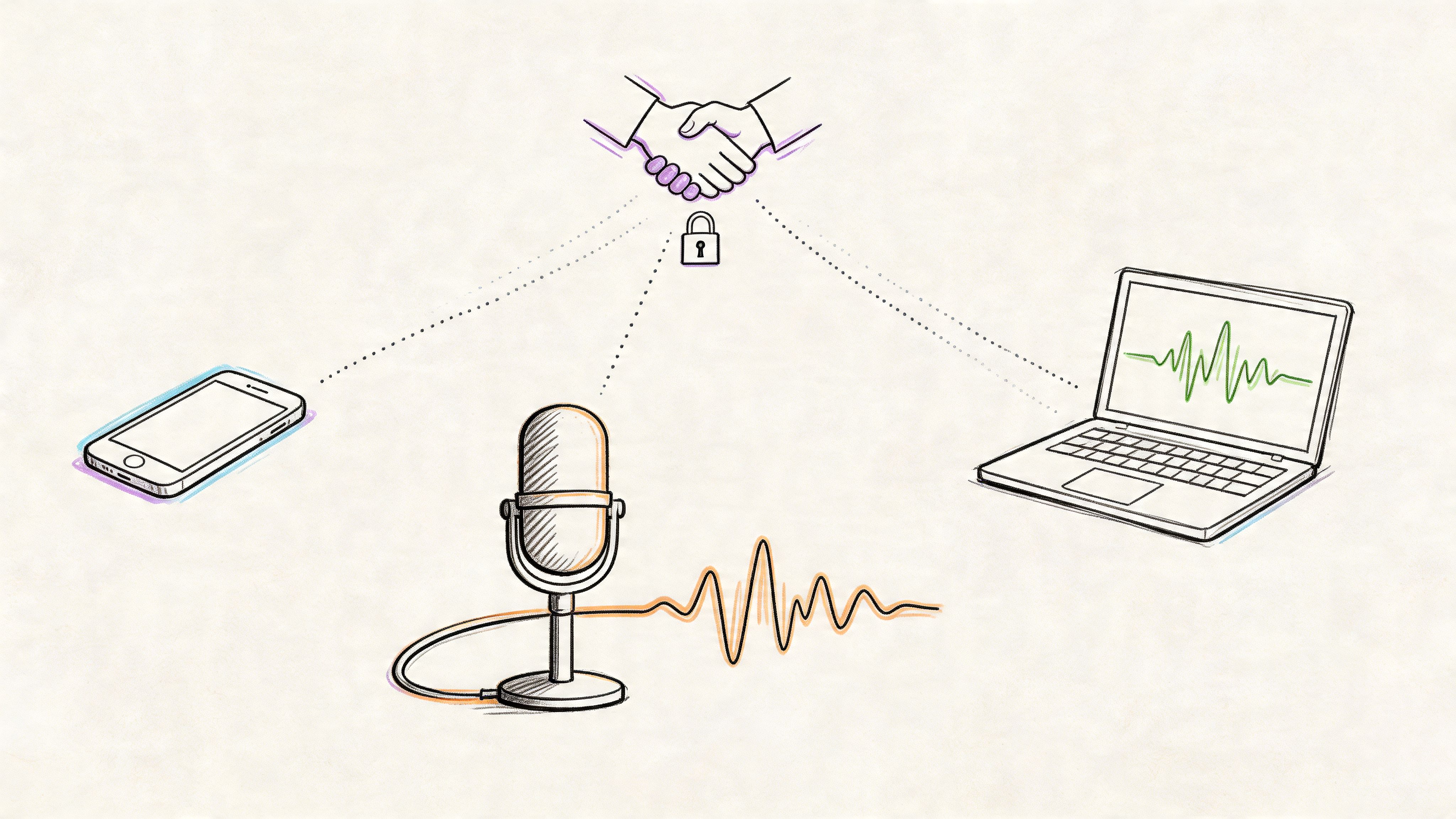
Is My Data Safe with Online Transcription Tools?
Uploading files, especially if they contain private or sensitive information, can feel a bit nerve-wracking. Your data privacy should be a major consideration when choosing an audio-to-text service. The good news is that trustworthy platforms take this very seriously and build their systems around protecting your information.
When you're comparing tools, look for these clear signs of a commitment to security:
- End-to-end encryption, which scrambles your files so no one can access them during upload or processing.
- A clear privacy policy that guarantees your data won’t be used to train AI models without your permission.
- Secure data handling that ensures your files are deleted promptly after processing.
Always go with a service that puts your privacy first, especially if you’re transcribing confidential business meetings, personal voice notes, or sensitive interviews.
Ready to see what top-tier transcription can do for you? Whisper AI combines incredible accuracy with speaker identification, automatic summaries, and rock-solid privacy. Try it for free and turn your audio into searchable, readable text in minutes.