A Guide to Modern Voice to Text Technology
At its most basic, voice to text is technology that turns spoken words into written text. Think of it as a digital scribe, listening to what you say and typing it out on a screen. It’s a simple concept, but it has become a fundamental part of how we interact with our devices every day.
How Does Voice to Text Actually Work?
Have you ever wondered how your phone can perfectly understand your request for directions or transcribe a rambling thought into a neat text message? The process might feel like magic, but it’s really a fascinating journey from a sound wave to a written word. It's less about wizardry and more like teaching a computer to listen and understand, almost like a person learning a new language.
At its heart, the technology follows a clear, logical path. It doesn't just "hear" words; it carefully dissects sound into its most basic parts to piece together the meaning.
The Journey From Sound to Text
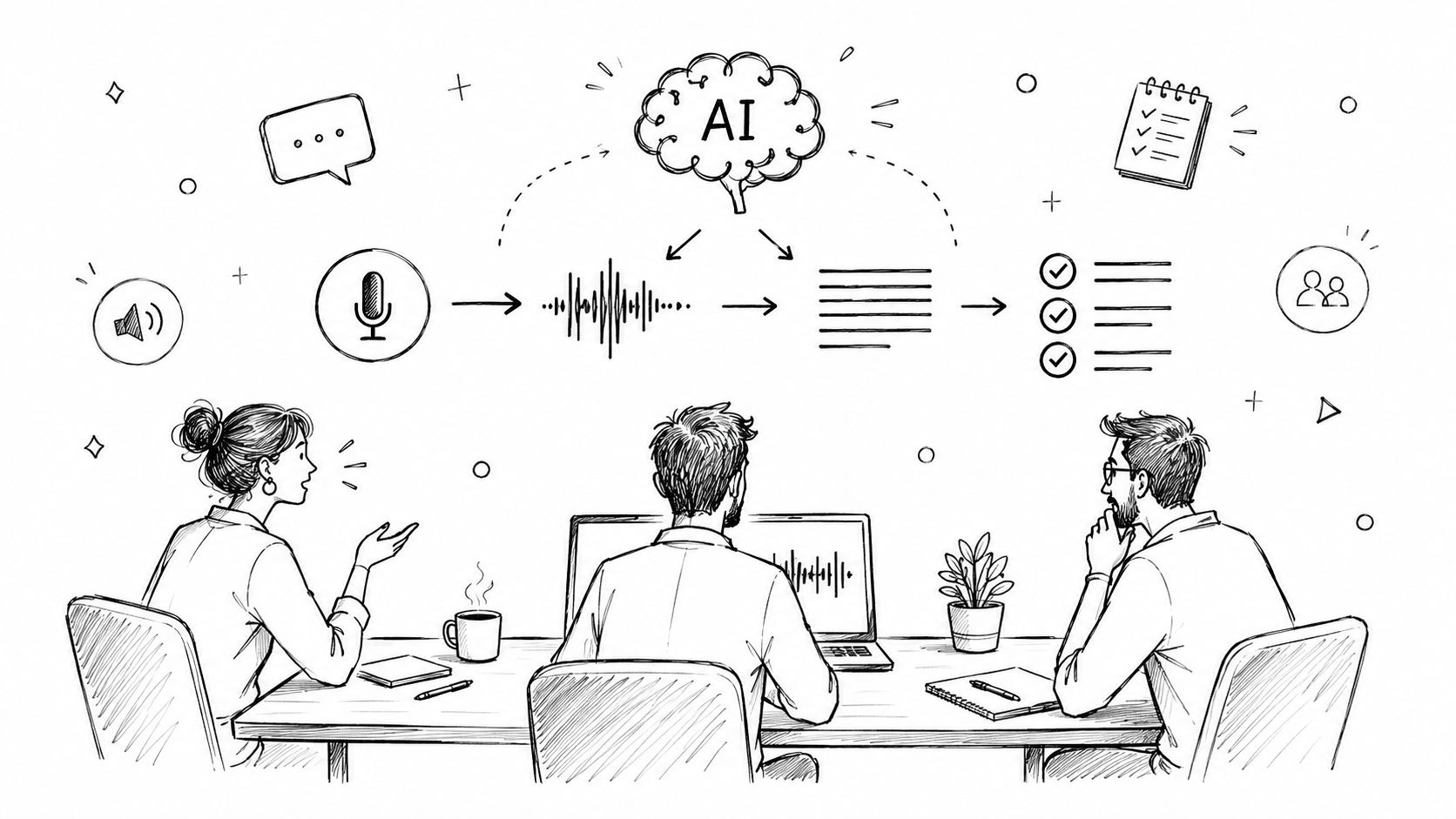
It all starts the moment you speak. A microphone in your smartphone, laptop, or smart speaker captures the sound waves your voice makes. These are analog waves, which get converted into a digital signal—a language the computer can process, made up of ones and zeros. This digital version of your voice is the raw material the AI gets to work with.
From there, the system breaks down this digital audio into the smallest units of sound, called phonemes. You can think of phonemes as the fundamental building blocks of speech. For instance, the word "chat" is made up of three phonemes: "ch," "a," and "t." The AI sifts through these sounds, comparing them against a huge library of known phonemes to figure out which ones you actually spoke.
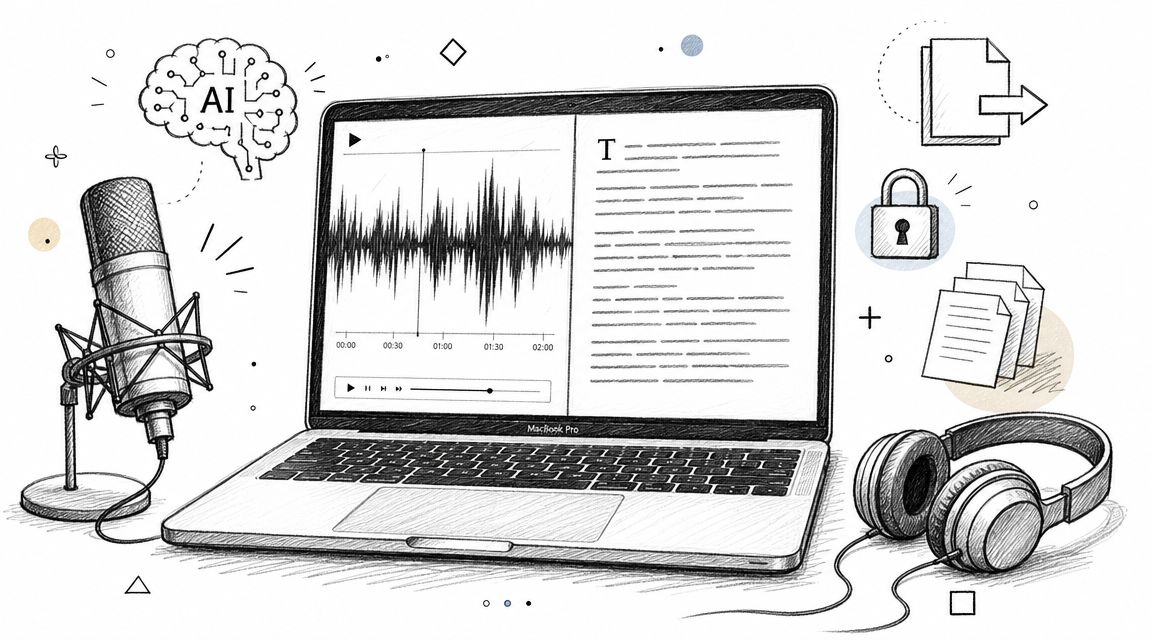
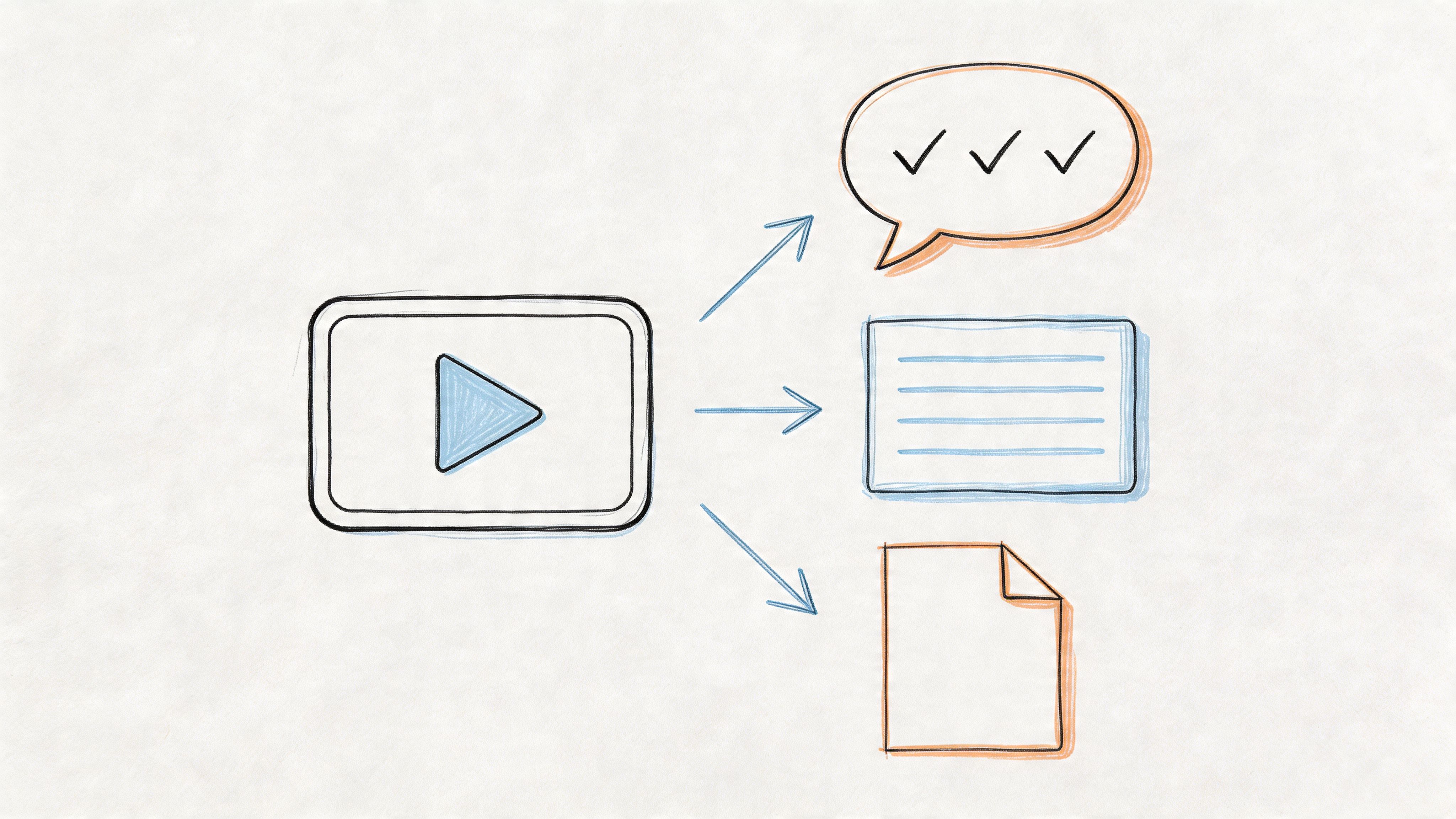
This infographic gives a great visual overview of how a spoken sound wave gets turned into digital info and, finally, into readable text.
As you can see, it's a multi-step process that takes a physical action—speaking—and translates it into a format that software can analyze and make sense of.
To make this a bit clearer, let's break down the conversion process into four key stages.
The Four Stages of Voice to Text Conversion
This final stage—language modeling—is where the real intelligence shines through, making the output sound natural and human.
Assembling Words and Sentences
Once the phonemes are sorted out, the AI's next job is to string them together to form words. It uses complex statistical models to figure out the most likely word based on the sequence of sounds it detected. For example, if it hears the phonemes for "h-ow," "ar," and "y-ou," it predicts the words are "how," "are," and "you."
But just identifying individual words isn't enough to create a coherent sentence. This is where the final, and most impressive, step comes in.
The system uses a language model to analyze the context of the words. It predicts which words are likely to follow one another, corrects for similar-sounding words (like "to," "too," and "two"), and adds punctuation to form a grammatically correct sentence.
This contextual understanding is what separates today’s voice to text tools from the clunky dictation software of the past. It’s the reason you can speak naturally and trust the technology to figure out not just what you said, but what you actually meant.
The AI Brain Behind Modern Speech Recognition
When you speak to a modern voice to text tool, the transcription that appears on your screen feels almost instant. But behind that smooth experience is a powerful AI system working incredibly fast. It helps to think of this system as a digital brain with two specialized parts, each handling a different but crucial job to turn your speech into text.
The first part is the Acoustic Model. This is the system’s set of ears. Its whole purpose is to listen intently to the audio it receives and match those raw soundwaves to the fundamental units of speech we talked about earlier—the phonemes.
Essentially, the Acoustic Model is trained to know what human language sounds like. It’s what allows the AI to distinguish between the subtle acoustic cues in words like "ship" and "sheep" or "cat" and "that." This initial sound-to-phoneme mapping is the first make-or-break step.
From Sounds to Sentences
Once the Acoustic Model has broken down the audio into a string of phonemes, the second part of the AI brain kicks in: the Language Model. If the Acoustic Model is the ear, the Language Model is the linguistic expert that understands context and structure.
It takes that stream of phonemes and starts figuring out the most likely sequence of words. It’s constantly asking, "Based on the words I've already transcribed, what word makes the most sense next?" This is how it deciphers the difference between "I need to write this down" and "Turn right at the corner," using the surrounding words to nail the correct one.
A strong Language Model is what separates a jumble of correctly identified words from a coherent, readable sentence. It’s the component that understands grammar, syntax, and phrasing, making the final output actually useful.
How does it get so smart? These models are trained on absolutely massive datasets of written text—think millions of books, articles, web pages, and transcripts. By analyzing this enormous library, the AI learns the patterns, rules, and subtle nuances of how we communicate.
How Neural Networks Learn to Listen
So, how do these models actually "learn"? The magic behind it all is neural networks, a type of AI that’s loosely modeled after the connections in a human brain. These networks are built with layers of interconnected nodes (or "neurons") that process information and get better over time.
To train a voice to text model, developers feed it thousands upon thousands of hours of audio that has already been accurately transcribed by humans. As the neural network listens to the audio and compares its own transcription to the correct one, it continuously adjusts its internal connections to get closer to the right answer. If you're curious about the nuts and bolts, you can learn more about how AI turns audio into text and the specific models involved.
This training process is what allows the AI to recognize patterns that would be far too complex to code by hand. It learns to handle the messy reality of human speech.
- Noise Reduction: The AI gets good at zeroing in on the speaker's voice and tuning out background chatter, traffic, or music.
- Accent Adaptation: By learning from a diverse range of speakers, the model becomes proficient at understanding various regional accents and dialects.
- Speaker Variation: The system adapts to an individual’s unique pitch, speaking speed, and enunciation.
Today’s top systems rely on a technique called deep learning, which just means using neural networks with many, many layers (that’s the "deep" part). Each layer learns to spot increasingly complex features, starting with basic sounds and building all the way up to full sentences. This layered approach is what gives the best voice to text tools their incredible precision, with some achieving over 95% accuracy in good conditions. This constant learning is what has elevated the technology from a clunky gimmick to a reliable tool we use every day.
Key Milestones in Voice Recognition History

The seamless voice to text technology we use today didn't just appear overnight. It's the product of decades of grinding research, countless experiments, and slow, hard-won breakthroughs. The path from room-sized machines to the AI in our pockets is a testament to relentless innovation.
Long before a smart speaker could add milk to your shopping list, engineers were wrestling with the challenge of teaching a machine to understand a person's voice. Their initial efforts were incredibly basic, focusing on recognizing just a few words spoken by one specific person in a perfectly quiet room.
Even with those limitations, these early projects proved the concept wasn't science fiction. They laid the groundwork for bigger ambitions and caught the eye of researchers and government agencies who saw the potential of a hands-free way to command computers.
The Dawn of Digital Speech Recognition
The story of speech recognition begins not in a startup garage, but in the massive research labs of legacy tech companies. These weren't consumer gadgets; they were ambitious projects pushing the boundaries of what was computationally possible at the time.
A huge first step came from Bell Laboratories in 1952 with a system they called 'Audrey.' It was an enormous piece of hardware, but it could recognize spoken digits from zero to nine—a remarkable feat for its era. Audrey was the proof of concept the field needed, demonstrating that distinct vocal patterns could be identified by a machine.
Ten years later, in 1962, IBM revealed its "Shoebox" machine. This device went a bit further than Audrey, understanding 16 different English words that included simple math commands. It was a tiny expansion of vocabulary, but it was a critical one, inching the technology closer to something practical.
These early devices were monumental achievements. They were speaker-dependent, meaning they had to be trained to a single voice, and could only handle isolated words, but they laid the essential groundwork for everything that followed.
These early wins in the 1950s were just the beginning. The field started to heat up in the 1970s, largely fueled by programs like the DARPA Speech Understanding Research initiative. This funding led to systems like Carnegie Mellon University’s Harpy, which could recognize over 1,000 words. You can dig deeper into the origins of voice recognition to see how these initial breakthroughs evolved.
The Statistical Revolution
The 1980s brought a seismic shift in how we approached voice to text. Researchers started using a powerful new statistical method called the Hidden Markov Model (HMM), and it completely changed the game.
Instead of trying to match sounds to a rigid, pre-defined template, HMMs work with probabilities. An HMM-based system could analyze a stream of audio and calculate the most likely words and sentences it represented, even when faced with different accents or pronunciations.
This statistical approach made the technology far more resilient and flexible. It could handle much larger vocabularies and wasn't so easily tripped up by different speakers or a bit of background noise. For nearly 30 years, HMMs were the backbone of almost every speech recognition system out there.
This leap forward led to far more capable systems, like IBM's voice-activated typewriter "Tangora," which boasted a vocabulary of 20,000 words. The move to HMMs took the field from recognizing single words to tackling the much bigger problem of continuous, natural speech, directly setting the stage for the tools we use every day.
How Voice to Text Became an Everyday Tool
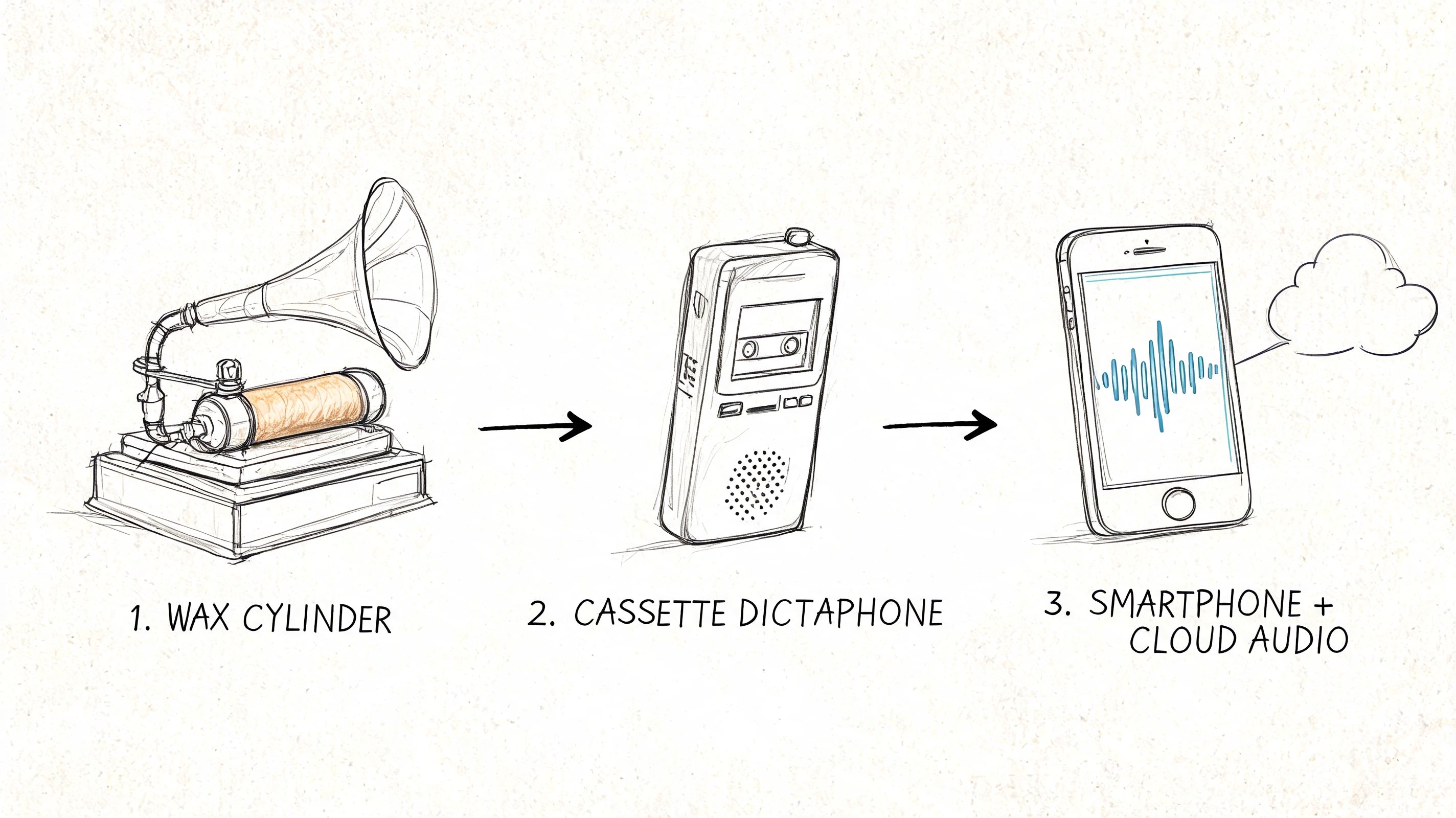
For many years, speech recognition was a fascinating but impractical technology. Early systems proved what was possible, but they were a long way from being useful, affordable, or easy enough for the average person to use. The real shift began when this technology finally broke out of the research lab and landed on home computers, powered by the rise of consumer software, cloud computing, and the smartphone in everyone's pocket.
From Niche Software to Your Smartphone
The first consumer-friendly speech recognition products started showing up in the 1990s, giving people their first real taste of talking to a computer and having it understand them. A landmark moment was the release of Dragon Dictate in 1990, the first widely available tool that let you speak directly to your PC and watch the words appear. It was slow and clunky by today's standards, but it was a start. The technology took another leap forward with Dragon NaturallySpeaking in 1997, which introduced continuous speech recognition, meaning you no longer had to pause awkwardly between each word.
These Dragon products set the standard for dictation for years to come. This period marked a shift from niche dictation tools to the everyday voice interaction technologies we now see in smartphones, virtual assistants, and more, which significantly broadened global adoption.
The Cloud and AI Acceleration
The real game-changer for voice to text was the rise of the internet and cloud computing. Training an AI model to understand human speech requires enormous amounts of data and processing power—far more than a personal computer could ever handle.
Cloud computing solved this problem. Companies could now process massive datasets of audio and text on powerful remote servers. This ability to train AI on a global scale led to a massive jump in accuracy. At the same time, high-speed internet made it possible for any device, from a smartphone to a smart speaker, to send a voice command to the cloud and get a response back in seconds.
This is the model that powers the voice assistants we use today. When you ask Siri for the weather or tell Google Assistant to set a timer, your voice is sent to a powerful cloud-based AI for processing. This shift from local processing to cloud-based intelligence is what made voice technology fast, accurate, and accessible to everyone.
Voice Search and Mobile Integration
The final piece of the puzzle was the smartphone. Tech giants like Google saw the huge potential of integrating voice commands directly into their core products. When Google integrated voice search into its mobile app, it didn't just add a feature; it changed how millions of people interact with the internet.
Instead of typing "best Italian restaurants near me," you could simply ask your phone. This seamless integration turned a specialized tool into a natural, everyday habit. Today, billions of voice searches are processed every month, and voice commands are a standard feature in everything from cars and TVs to kitchen appliances. The journey from the lab to our daily lives was complete, making voice a primary way we interact with technology.
Practical Ways to Use Voice to Text
Understanding the science behind turning sound into words is one thing, but seeing how it genuinely changes things in the real world is another. Voice-to-text technology isn't just a neat trick for sending a quick message anymore. It's become a foundational tool in countless professions, saving immense amounts of time, making content accessible to more people, and even uncovering brand-new insights.
Across the board, from newsrooms to classrooms, professionals can now turn hours of recorded audio into searchable, editable text in a matter of minutes. This completely sidesteps the old, painstaking process of manually typing everything out, freeing people up to focus on the actual substance of their work.
Enhancing Productivity for Creators and Professionals
For anyone who works with a lot of spoken information—content creators, journalists, researchers—voice-to-text is an absolute game-changer. It automates one of the most tedious parts of the workflow, letting them get more done, faster.
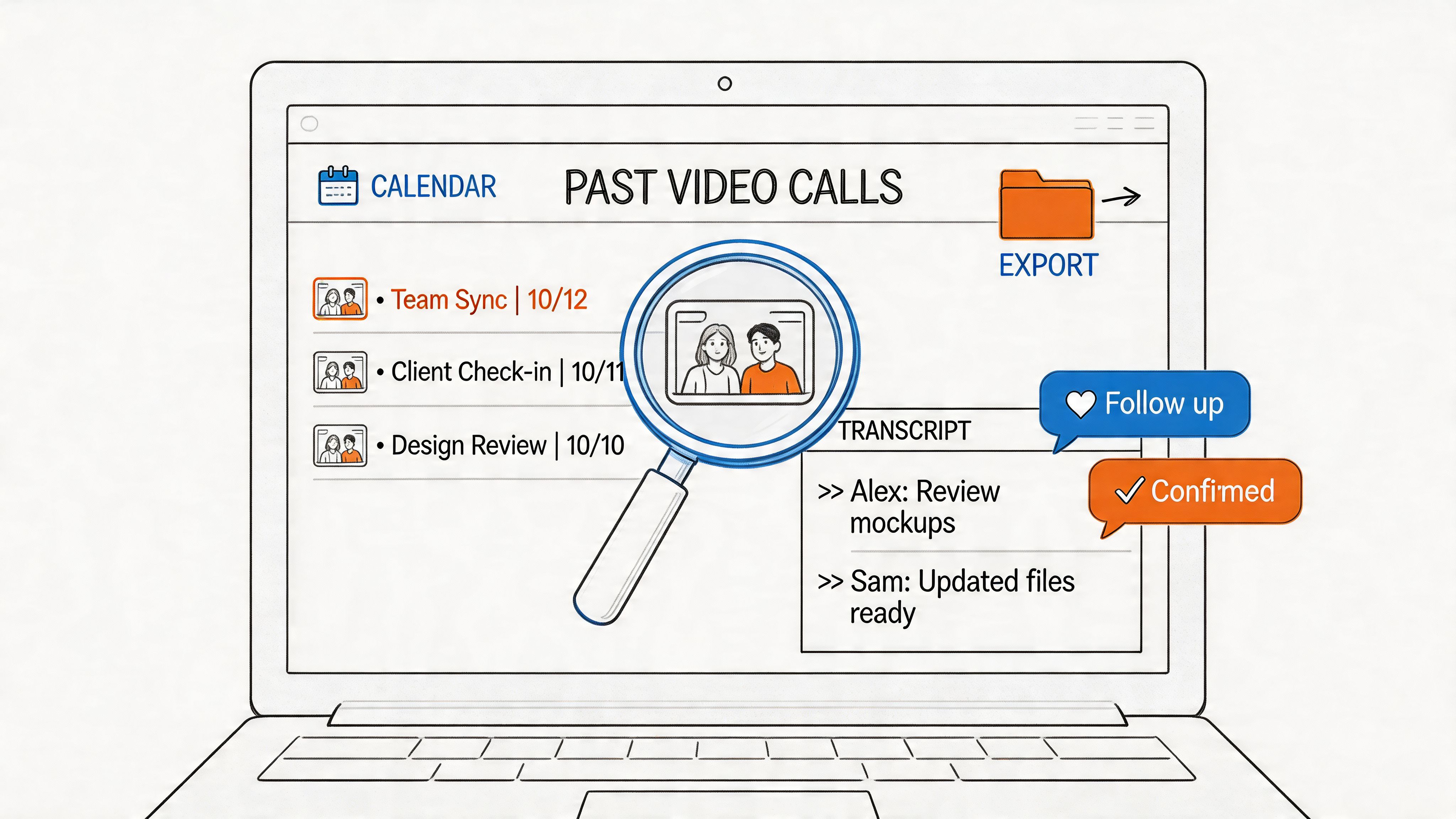
Picture a journalist in the middle of a critical interview. Instead of constantly pausing to scribble notes or dreading the hours of transcription ahead, they can get a full transcript almost instantly. This lets them pinpoint key quotes, double-check facts, and start writing their story while the conversation is still fresh in their mind.
It's the same for students. They can record a lecture, convert it to text, and suddenly have a perfect, searchable study guide. No more trying to keep up with a fast-talking professor or trying to make sense of messy notes later.
The core benefit is simple but profound: turning spoken dialogue into a tangible, digital asset. This makes audio and video content as searchable and useful as any written document, opening up countless possibilities for analysis and reuse.
This simple shift has a massive impact on how people get their work done every single day.
Improving Accessibility and User Experience
Beyond saving time, voice-to-text plays a crucial role in making the digital world open to everyone. For anyone creating video content, accurate captions are no longer a "nice-to-have"—they're essential for reaching the widest possible audience.
Here’s how it helps different groups:
- Deaf and Hard of Hearing: Captions are the bridge that makes video content accessible to millions of people who couldn't engage with it otherwise.
- Non-Native Speakers: For viewers learning a new language, reading along with the audio is a powerful tool for improving comprehension.
- Public Viewing: A huge chunk of social media videos are watched without sound. Captions make sure the message lands, even in a silent scroll.
Developers are also weaving voice commands directly into apps and devices. This is a huge win for users with mobility challenges, allowing them to navigate software and operate technology completely hands-free. It’s a powerful step toward a more inclusive user experience.
Driving Insights in Business and Healthcare
The applications of voice-to-text go far beyond general productivity, reaching deep into specialized fields where they provide critical intelligence and better care.
Take the medical field, for example. Doctors are increasingly using dictation to capture patient notes. It's often much faster and allows for more detail than typing, which means better records and, more importantly, more time to actually talk with patients.
To see just how versatile this technology is, here’s a quick look at how a few different industries are putting it to work.
Voice to Text Use Cases Across Industries
As you can see, the core function—turning speech into text—unlocks unique value depending on the context, from improving patient outcomes to streamlining legal workflows.
Call centers are another prime example. By transcribing customer service calls, companies can:
- Analyze Sentiment: AI can scan the transcripts to get a feel for customer satisfaction, spot common complaints, and identify trends as they happen.
- Ensure Compliance: The transcripts create a perfect record, helping businesses verify that agents are following legal scripts and internal policies.
- Improve Training: Managers can review call transcripts to see where agents are excelling or where they might need more coaching, leading to much more targeted and effective training.
These examples show that converting speech to text isn't just about creating a document. It's about unlocking the incredibly valuable data that’s hidden inside all those spoken conversations. To learn more about the engines that make this possible, you can find a deeper dive into the world of speech to text AI tools and what they're capable of. The technology is fundamentally changing how organizations operate by turning unstructured audio into truly actionable information.
What Affects Transcription Accuracy
While today's voice to text tools can feel like magic, they aren't perfect. We've all been there: one minute, it nails a complex technical phrase, and the next, it butchers a simple name. This inconsistency isn't random. The final quality of any transcript hinges on a few critical factors that can make or break the AI's performance.
The biggest one? Audio quality. It’s really that simple.
Think of the AI as a person trying to listen to you from across a noisy, crowded room. If you're mumbling or facing away, even a human would have trouble catching every word. The same goes for the AI. When the audio is muddy, the system has to guess, and that’s where mistakes creep in.
The Impact of Audio Clarity
The old programmer’s mantra, "garbage in, garbage out," is the golden rule of transcription. No matter how advanced the AI is, it can't understand what it can't hear. Several things feed into audio quality, and paying attention to them is your first and best step toward a flawless transcript.
Here's what makes the biggest difference:
- Microphone Quality: Your laptop's built-in mic is okay for a quick voice memo, but it doesn't compare to a dedicated external microphone. Better mics capture a much cleaner signal. We're even starting to see new hardware like microphones with auto-focus for voice designed to solve this exact problem.
- Background Noise: A humming air conditioner, nearby conversations, or street traffic all compete with the speaker's voice. This extra noise confuses the AI, making it harder to isolate what’s important.
- Speaker Proximity: The closer someone is to the mic, the stronger the signal. A strong, direct signal leaves little room for ambiguity and dramatically reduces errors.
Getting these elements right gives the AI clean data to work with. If you want to dive deeper into getting your setup just right, our guide to AI-powered transcription services has some great tips on audio prep.
Human Factors in Speech Recognition
Beyond the tech, the way people actually talk has a massive impact. Human speech is a beautiful, messy thing filled with quirks that can trip up an AI trained on "standard" language.
Every speaker has a unique vocal fingerprint. An AI's ability to accurately transcribe speech depends on how well its training data represents the diversity of these human voices.
Things like heavy accents, a rapid-fire speaking pace, or lots of regional slang can throw a model for a loop. The best systems are getting much better at understanding this variety, but very strong accents or uncommon speech patterns can still cause problems.
Vocabulary also plays a huge role. An AI trained on everyday language might struggle with dense medical or legal jargon. The same goes for unique brand names or acronyms that weren't part of its training diet. Keeping these human elements in mind helps you know what to expect and how to get the cleanest transcript possible.
Answering Your Top Questions About Voice-to-Text

As voice-to-text tools become a bigger part of our everyday work and personal lives, a lot of questions pop up. How does it actually work? What are its limits? How can I get better results? Let's clear the air and tackle some of the most common questions people have.
My aim here is to pull back the curtain on the tech and give you some solid, practical knowledge. Whether you're just starting out or you've been using these tools for a while, these answers should help.
How Is Voice-to-Text Different From Text-to-Speech?
This is easily one of the most common mix-ups, and it's understandable since both technologies live at the intersection of voice and text. But they're really just two sides of the same coin, performing opposite jobs.
Here’s the simplest way to think about it: voice-to-text is a listener. It takes your spoken words and turns them into written text. On the flip side, text-to-speech is a speaker. It takes a written document and reads it out loud in a synthesized voice.
If you want to dig a little deeper, you can explore the key differences between Text to Speech and Speech to Text in more detail. Getting this distinction right is the first step to picking the right technology for what you need to do.
To put it plainly: Voice-to-text transcribes what you say. Text-to-speech reads what you write.
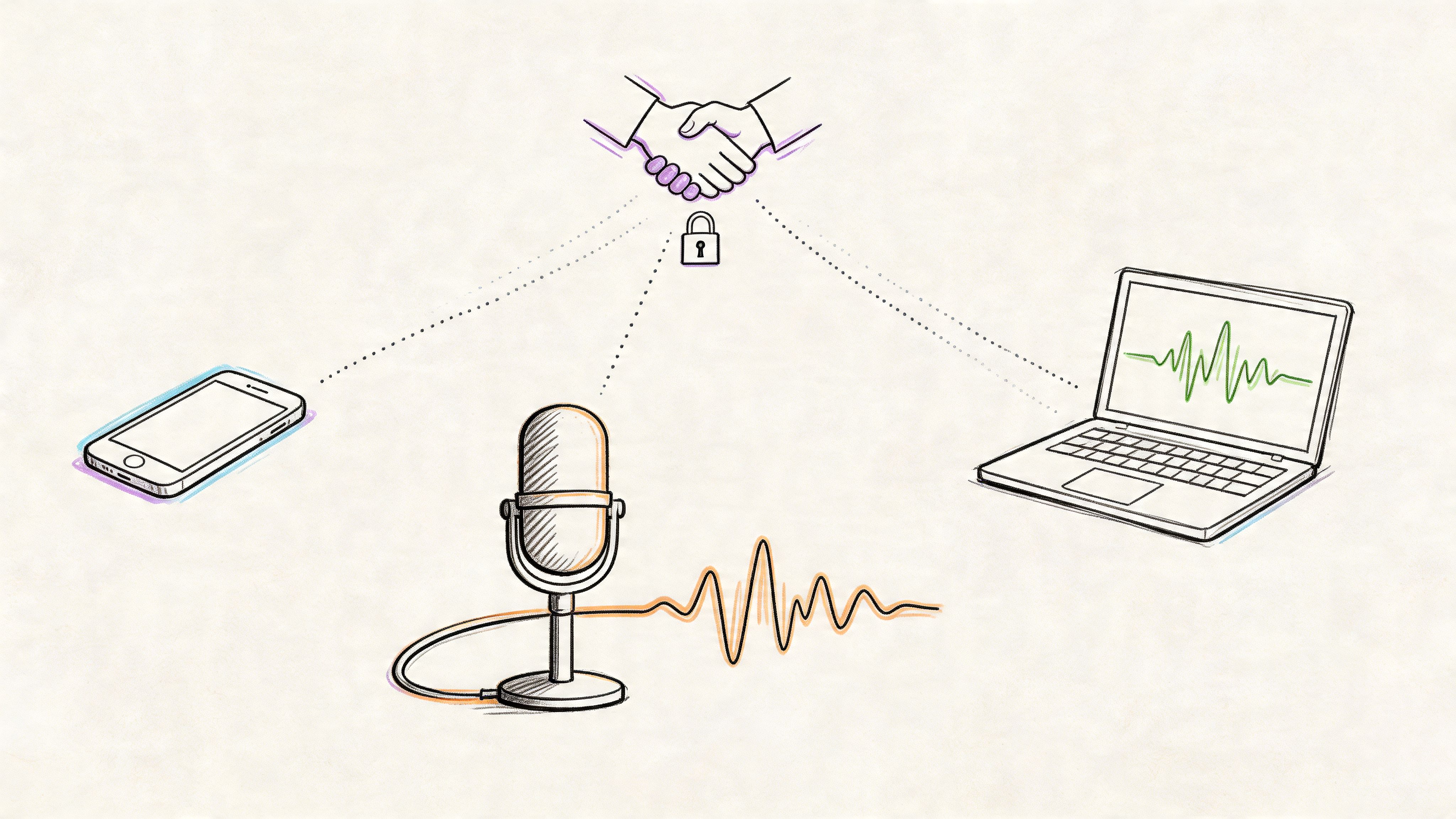
Is My Data Secure When Using These Tools?
With recordings of meetings or personal notes, data privacy is a huge and completely valid concern. The short answer is: it all comes down to the service provider you choose. Any reputable service will use strong encryption to keep your files safe, both on their way to the server and while being processed.
Most professional-grade tools are built with privacy in mind from the ground up. They have clear policies explaining that your data won't be held longer than necessary and won't be used for anything other than your transcription. It’s always smart to read the privacy policy before you upload anything sensitive.
Here are a few things to look for:
- End-to-end encryption: This locks down your data from the moment it leaves your computer.
- Clear data retention policies: The service should tell you how long they keep your files and let you delete them.
- Compliance with standards: If you deal with personal data, look for compliance with regulations like GDPR.
Can Voice-to-Text Handle Multiple Languages?
Absolutely. Modern speech recognition systems are linguistic powerhouses. The best platforms can transcribe dozens of languages, and some are even smart enough to figure out what language is being spoken without you telling them.
This incredible flexibility comes from training the AI on massive, global datasets of spoken language. That’s what makes this technology so useful for international businesses, content creators with a global audience, and researchers who work with sources from all over the world.
Ready to stop typing and start talking? Whisper AI offers highly accurate transcription in over 92 languages, complete with automatic summaries and speaker detection. Turn your audio and video into clear, actionable text today. Get started with Whisper AI.