Что такое языковые модели и как они работают?
По своей сути, языковая модель — это специализированный искусственный интеллект, обученный понимать и создавать человеческий язык. Исходя из моего опыта работы с такими инструментами, лучше всего представить её как сверхмощный автозаполнение, прочитавший огромную часть интернета. Эти модели — это движки, работающие за кулисами многих инструментов ИИ, которые вы, вероятно, уже используете, от поисковой строки до современных сервисов транскрипции.
Что такое языковые модели и почему они важны?
Языковая модель — это искусственный интеллект, который учится обрабатывать, понимать и генерировать текст, воспринимаемый человеком. Он достигает этого, анализируя огромные массивы текстовых данных — бесчисленные книги, статьи и веб-сайты — чтобы изучить закономерности, грамматику и тонкие правила нашего общения. Этот масштабный процесс обучения учит его предсказывать следующее слово в предложении, что является основополагающим навыком для самых разных профессий, связанных с языком.
Проще говоря, эти модели — это основа многих интеллектуальных инструментов, на которые сегодня полагаются профессионалы. Они выходят далеко за рамки простого распознавания ключевых слов; они предназначены для определения истинного значения используемых вами слов. Это знаменует собой серьезный сдвиг в том, как мы взаимодействуем с нашими устройствами, превращая их из простых машин в партнеров по сотрудничеству. Чтобы увидеть самые продвинутые версии этой технологии, стоит понять специфику больших языковых моделей — самых больших и мощных версий, доступных сегодня.
Для краткого обзора в этой таблице подробно описано, что делают эти модели и какую пользу они приносят, исходя из моего непосредственного опыта их использования.
Языковые модели вкратце
В конечном счете, языковая модель переводит хаотичную, неструктурированную природу человеческого языка в формат, с которым может работать компьютер, открывая доступ к практическим решениям для повседневных профессиональных задач.
Реальное влияние на вашу работу
Ажиотаж вокруг языковых моделей — это не просто шумиха; речь идёт о реальной эффективности и открытии новых способов работы. Я обнаружил, что они берут на себя рутинные задачи и открывают творческие возможности, которые раньше были непрактичны. Для всех, кто работает со словами или информацией, эти инструменты быстро становятся незаменимыми.
Так что же делает их такими важными для профессионалов?
- Повышение производительности: они могут за считанные минуты расшифровать многочасовое совещание, свести объемный отчет к нескольким пунктам или составить черновики электронных писем, освободив ваше время для более стратегической работы.
- Более четкая коммуникация: помогая вам отточить навыки письма, выявить грамматические ошибки или даже перевести текст между языками, эти модели гарантируют, что ваше сообщение будет воспринято именно так, как задумано.
- Более глубокий анализ: они могут просматривать тысячи отзывов клиентов или искать информацию в огромных архивах, чтобы выявлять тенденции и извлекать ключевые сведения, которые человек мог бы легко упустить.
Истинная сила языковой модели заключается в ее способности управлять сложностью человеческого языка в огромных масштабах. Она понимает контекст, делает выводы о значении и создает связный текст, превращая необработанную информацию в ценный, структурированный ресурс.
Эти модели являются ключевым компонентом более широкой области, называемой обработкой естественного языка. Если вам интересно узнать о науке, которая делает все это возможным, наше руководство по обработке естественного языка станет отличной отправной точкой.
От простых правил к интеллектуальному искусственному интеллекту
Путь к современным сложным языковым моделям не был внезапным скачком; это история, которая разворачивалась на протяжении десятилетий. Первые попытки научить компьютеры понимать язык основывались на простых, жестко запрограммированных правилах. Эти системы были невероятно негибкими, способными обрабатывать только очень специфические задачи, для которых они были специально запрограммированы — подобно простому калькулятору, который знает лишь несколько операций, для выполнения которых он был создан.
Этот основанный на правилах подход впервые получил широкое распространение в середине XX века. В 1954 году эксперимент, проведенный Джорджтаунским университетом и IBM, показал, как машина переводит 60 русских предложений на английский. Это было знаковое событие, но сама система была довольно примитивной, работая всего на 6 грамматических правилах и крошечном словаре из 250 слов. Тем не менее, это было подтверждением концепции. Это показало, что теоретически машина может обрабатывать человеческий язык. Вы можете изучить полную историю этих ранних разработок и увидеть, как они проложили путь всему последующему.
Настоящая проблема этих ранних моделей заключалась в их неспособности к обучению. Они не могли адаптироваться к новым словам, сленгу или бесконечным исключениям, которые делают язык таким запутанным и человечным. Каждое правило приходилось кропотливо прописывать человеку.
Переход к обучению на основе данных
Следующий крупный прорыв произошел, когда исследователи начали использовать статистические модели . Вместо того чтобы давать компьютерам список правил, они загрузили в них огромные объемы текста и позволили моделям самим выявлять закономерности. Анализируя, какие слова часто встречаются вместе, они смогли начать предсказывать следующее слово в предложении, основываясь исключительно на вероятности. Это был огромный шаг вперед. Впервые модели обучались на основе реального языка, а не жесткого, заранее запрограммированного сценария.
Этот новый статистический подход привел к появлению нескольких ключевых типов моделей, которые продвинули эту область вперед:
- N-граммовые модели: Они довольно просты. Они предсказывают следующее слово, анализируя предыдущие "n" слов. Например, 2-граммовая (или биграммовая) модель, увидев "thank you", может предсказать "very" просто потому, что "thank you very" — это распространённая статистическая пара в тексте, на котором она обучалась.
- Рекуррентные нейронные сети (РНН): Значительное усовершенствование, РНН ввели концепцию «памяти». Они могли сохранять информацию из предыдущих частей предложения, что позволяло им понимать гораздо более сложную грамматику и контекст.
- Долговременная кратковременная память (LSTM): LSTM представляли собой особый тип рекуррентных нейронных сетей (RNN), разработанный для устранения существенного недостатка. Ранние RNN имели тенденцию «забывать» то, что происходило в начале длинного предложения, к моменту его завершения. LSTM гораздо лучше запоминали информацию на протяжении более длинных фрагментов текста, что делало их гораздо более эффективными.
Расцвет нейронных сетей
Эти статистические методы заложили основу для мощных нейронных сетей, которыми мы располагаем сегодня. Вдохновленные взаимосвязанной структурой человеческого мозга, нейронные сети феноменально способны распознавать невероятно тонкие и сложные закономерности в языке. Они не просто подсчитывают, как часто слова встречаются вместе; они изучают глубинные, лежащие в основе взаимосвязи и контексты, которые на самом деле придают нашим словам смысл.
Эта эволюция — от простых правил к обучению на основе данных — действительно отличает современный ИИ от его предшественников. Это разница между машиной, которая просто следует строгому набору команд, и машиной, способной понимать, адаптироваться и даже генерировать тонкие нюансы человеческой коммуникации. Именно на этом фундаменте построены самые впечатляющие инструменты для работы с языком, существующие сегодня.
Как языковая модель учится «думать»
Итак, как языковая модель превращается из цифрового чистого листа в нечто, способное написать электронное письмо или составить краткое изложение объемного отчета? Этот процесс во многом похож на обучение очень, очень преданного своему делу ученика, но библиотека, которую она изучает, представляет собой огромный фрагмент интернета.
Этот огромный массив текста разбивается на более мелкие единицы, называемые токенами . Представьте токены как основные строительные блоки языка — это могут быть целые слова, такие как «привет», части слов, например, «-ing», или даже просто запятая. Например, простая фраза «что такое языковые модели» скорее всего будет разделена на четыре токена: ["what", "are", "language", "models"] .
В процессе обучения модель преследует одну главную цель: предсказать следующий токен в последовательности. После того, как ей показывают токены ["what", "are", "language"] , её задача — определить, что "models" является наиболее вероятным следующим токеном. Она делает это снова и снова, миллиарды раз, и в процессе начинает усваивать сложные закономерности, грамматику и контекстуальные нюансы человеческого языка.
Сила внимания
Долгое время одной из главных проблем языковых моделей было отслеживание контекста на протяжении длинных текстовых фрагментов. Ранние модели обладали короткой памятью; они могли забыть начало абзаца к тому моменту, когда добирались до конца. Все изменилось в 2017 году с появлением архитектуры Transformer .
В Transformers появилась революционная концепция: механизм внимания . Он позволяет модели оценивать важность различных слов при попытке сделать прогноз. По сути, она может «обращать внимание» на наиболее релевантные части входных данных, независимо от того, где они встречаются в тексте.
Например, рассмотрим предложение: «Робот поднял красный мяч, потому что он был ближе всех». Механизм внимания помогает модели правильно определить, что « он » относится к «мячу», а не к «роботу». Эта способность связывать связанные идеи в рамках предложения стала огромным прорывом.
На этом графике показано, как языковые модели эволюционировали от простых, жестких систем до сложных моделей-трансформеров, которые мы видим сегодня.
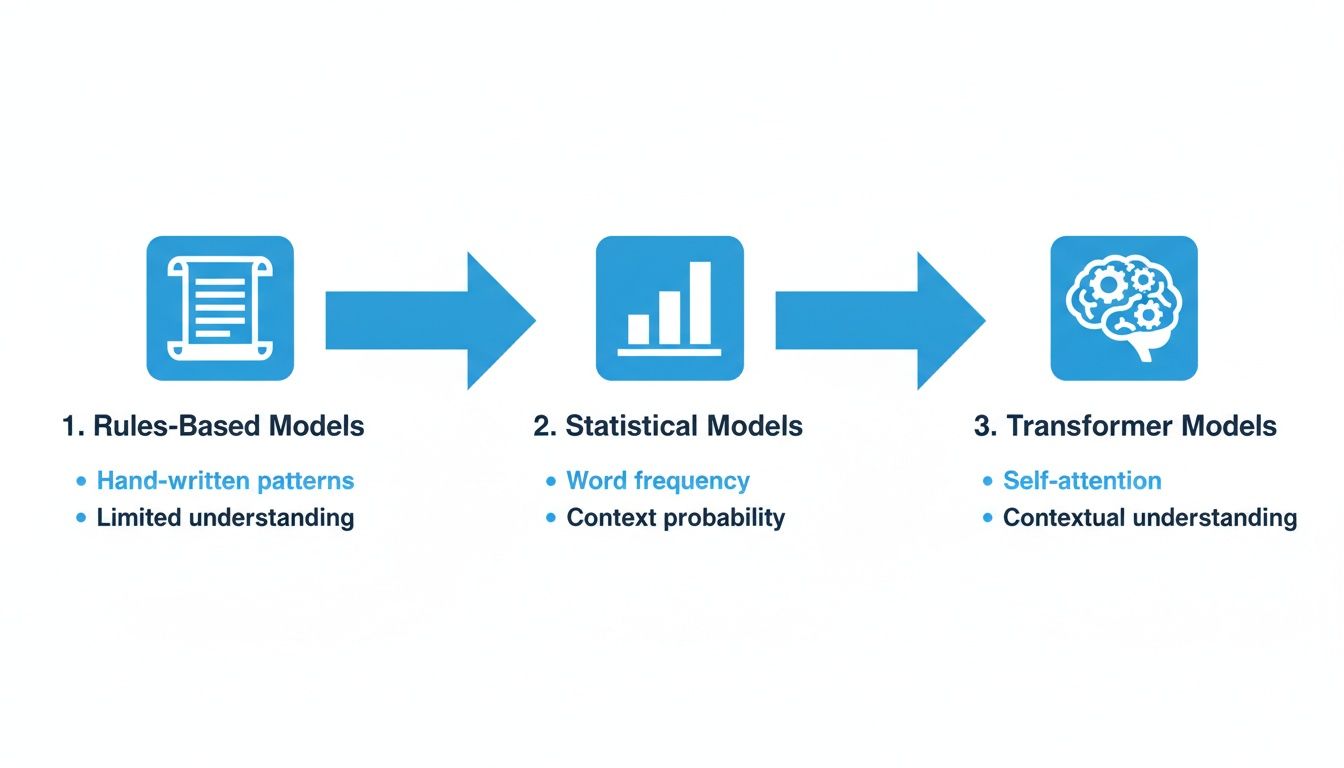
Как видите, путь начинается с базовых правил, переходит к статистическим вероятностям и, наконец, к глубокому контекстному пониманию, которое определяет современный искусственный интеллект.
Построение взаимопонимания, кирпичик за кирпичиком.
Именно этот интенсивный процесс обучения наделяет языковую модель способностью «думать». Это не сознательное мышление, как у человека, а скорее невероятно продвинутая форма сопоставления образов. Модель накапливает знания слой за слоем:
- Статистические зависимости: Оно узнает, что слово «горячий» часто встречается рядом со словом «кофе», но редко рядом со словом «мороженое».
- Грамматическая структура: Она усваивает правила построения предложений, например, как за существительным обычно следует глагол.
- Контекстуальное значение: Выясняется, что слово «банк» имеет разное значение в выражениях «берег реки» и «банковский депозит».
Благодаря такому масштабному обучению на основе больших данных, модель строит сложную внутреннюю карту языка. Именно поэтому она может делать гораздо больше, чем просто предсказывать следующее слово. Она может обобщать, переводить и генерировать целые абзацы, потому что изучила лежащую в основе логику того, как слова соединяются, образуя значение.
Обзор различных типов языковых моделей
Не все языковые модели одинаковы. За прошедшие годы мы стали свидетелями нескольких существенных изменений в том, как мы обучаем машины понимать язык. Каждый новый подход привносил свои сильные стороны, и знание этих различий помогает объяснить, почему одни инструменты ИИ отлично подходят для простых прогнозов, а другие могут писать целые статьи.
Рассматривайте это как эволюцию. Мы начали с обучения машин простым статистическим приемам, затем наделили их своего рода памятью и, наконец, пришли к конструкции, которая позволяет им понимать общую картину.
От статистических предположений к нейронной памяти
Самые ранние языковые модели были чисто статистическими, и N-граммы были наиболее распространенными. N-грамма — это, по сути, простое сопоставление шаблонов. Например, 2-грамма (или биграмма) предсказывает следующее слово, анализируя только одно слово, которое предшествовало ему. Если она видит «thank you», она может предположить, что следующее слово — «very», просто потому что «thank you very» — распространенная пара в ее данных. Это грубый инструмент, эффективный для простых задач, но совершенно не понимающий истинного смысла предложения.
Ситуация стала интереснее с появлением рекуррентных нейронных сетей (РНН) . Эти модели ввели концепцию памяти. РНН обрабатывает предложение по одному слову за раз, но она может «помнить», что видела ранее в последовательности. Это был огромный шаг вперед, позволивший моделям обрабатывать более сложную грамматику. Популярный тип РНН, называемый сетью долговременной кратковременной памяти (LSTM) , оказался еще лучше в сохранении контекста на протяжении более длинных фрагментов текста.
Это было похоже на переход от попугая, способного повторять только общеизвестные фразы, к помощнику, который действительно помнит тему разговора, состоявшегося несколько предложений назад. Этот сдвиг был принципиально важен для того, чтобы машины действительно понимали язык.
Модели трансформаторов: современный золотой стандарт
Настоящий прорыв произошел в 2017 году с появлением архитектуры Transformer . Transformer отказались от пословной обработки текста. Вместо этого они разработали способ анализа всех слов в предложении одновременно, оценивая важность каждого слова по отношению к другим.
В этом и заключается волшебство невероятного понимания контекста, которое мы видим в таких моделях, как BERT и GPT. Именно так они могут улавливать тонкие взаимосвязи между словами, даже если они находятся далеко друг от друга в абзаце. Сегодня почти каждый продвинутый инструмент искусственного интеллекта — от поисковой системы, расшифровывающей сложный вопрос, до ИИ-помощника, составляющего профессиональное электронное письмо, — использует модель Transformer в качестве основы.
Чтобы оценить масштаб этих достижений, давайте кратко сравним эти архитектуры между собой.
Сравнение архитектур языковых моделей
Как видите, каждая модель представляет собой значительный скачок в способности машины обрабатывать сложность и нюансы человеческого языка.
Определение больших языковых моделей (LLM)
Это подводит нас к большим языковым моделям (LLM) . LLM — это не совершенно новая архитектура; это модель трансформера , масштабированная до колоссальных размеров. Речь идёт о моделях, обученных на невероятных объёмах данных, содержащих миллиарды, а иногда и триллионы параметров. Именно этот огромный масштаб раскрывает их удивительные способности к рассуждению, творческому письму и обработке сложных инструкций.
Инструменты, подобные тем, что лежат в основе Whisper AI, являются прекрасным примером того, как эти мощные модели используются для создания исключительно точных аудиозаписей и генерации содержательных резюме на основе устной речи.
Практическое применение в вашей повседневной работе
Теория, лежащая в основе языковых моделей, увлекательна, но их истинное предназначение проявляется в реальном мире. Давайте отойдем от абстрактных концепций и посмотрим, как эти модели лежат в основе инструментов, решающих реальные, повседневные задачи на работе. Цель проста: позвольте ИИ взять на себя трудоемкие языковые задачи, чтобы вы могли сосредоточиться на стратегии и высокоуровневом мышлении.
Подумайте о расшифровке аудиозаписей. Из собственного опыта я знаю, что часовое интервью может легко отнять несколько часов утомительного набора текста. Сервис расшифровки на основе искусственного интеллекта, построенный на сложной языковой модели, может превратить ту же самую аудиозапись в точный документ с возможностью поиска всего за несколько минут. Это прямой и огромный скачок в эффективности.
Автоматизация создания и управления контентом
Языковые модели не просто преобразуют речь в текст, они коренным образом меняют способы создания и управления контентом. Они могут взять простую идею и превратить её в самый разный письменный материал, помогая вам преодолеть этот ужасный «пустой лист» и ускорить весь рабочий процесс.
Вот несколько способов, которыми я лично их использовал:
- Создание черновика контента: Застряли на этапе написания поста для социальных сетей, плана для блога или сложного электронного письма? Языковая модель может предоставить вам надежный первый черновик за считанные секунды. Вам останется только доработать и персонализировать его.
- Обобщение информации: Вам нужно быстро понять 50-страничный отчет или объемную статью? Эти инструменты помогут свести все к краткому резюме или четкому списку пунктов, сэкономив вам часы чтения.
- Повторное использование медиаконтента: превратите эпизод подкаста в пост в блоге, выберите ключевые цитаты из видео для социальных сетей или создайте заметки к вебинару. Главное – максимально эффективно использовать уже имеющийся контент.
Решающим фактором является способность понимать намерения пользователя. Современные поисковые системы уже не просто сопоставляют ключевые слова. Они используют языковые модели, чтобы определить, что вы действительно ищете, поэтому результаты поиска сегодня гораздо более релевантны и полезны.
Раскрытие новых творческих и аналитических возможностей
Области применения не ограничиваются текстом. Языковые модели также интегрируются с другими творческими и аналитическими инструментами, открывая новые способы общения и поиска информации, которую раньше было невероятно сложно получить.
Например, генератор мемов на основе ИИ — забавная, но мощная иллюстрация этого. Базовая языковая модель понимает контекст изображения и нужный текст, а затем создает мем, который действительно актуален и смешон. Это творческая задача, решаемая с помощью ИИ.
Та же идея применима и к серьезному анализу. Компания может загрузить тысячи отзывов клиентов в языковую модель, чтобы мгновенно выявить общие темы, отследить настроения и определить болевые точки клиентов. Представьте, сколько времени это заняло бы у команды людей. В нашем руководстве по использованию ИИ для преобразования речи в текст более подробно рассказывается о том, как эта технология используется для получения подобных данных о клиентах.
Как только вы по-настоящему поймете , что такое языковые модели , вы начнете видеть возможности их применения повсюду. Это мощные помощники для транскрибирования, составления резюме, черновиков и анализа — превращающие медленные, ручные задачи в быстрые, автоматизированные процессы.
Понимание ограничений и будущего языка искусственного интеллекта
Языковые модели действительно впечатляют, но это не волшебство. Чтобы извлечь из них максимальную пользу и использовать их ответственно, мы должны честно признать их недостатки. Восприятие их как мощных, но несовершенных инструментов помогает нам стать более грамотными и критичными пользователями.
Одна из наиболее обсуждаемых проблем — это так называемые «галлюцинации» ИИ. Это происходит, когда модель уверенно выдает информацию, которая звучит совершенно разумно, но на самом деле неверна или просто выдумана. Поскольку цель ИИ — просто предсказать следующее логично звучащее слово, он легко может создавать убедительные предложения, совершенно оторванные от реальности. Внутреннего механизма проверки фактов нет; он будет утверждать вымысел с той же степенью достоверности, что и факт.
Ещё одним огромным препятствием является предвзятость . Эти модели обучаются на огромном количестве текста из интернета, а интернет, как известно, полон человеческих предубеждений, стереотипов и недостоверной информации. Искусственный интеллект учится на всём этом, и его результаты могут отражать и даже усиливать эти вредные идеи, что приводит к искажённым или несправедливым результатам. Исследователи активно работают над способами фильтрации этой предвзятости и создания более нейтральных моделей, но это сложная и постоянно решаемая задача.
Основная проблема заключается в том, что модель не «знает», что истинно, а что ложно; она знает только то, что статистически вероятно на основе обучающих данных. Это различие является ключевым для понимания как ее возможностей, так и ее недостатков.
Ориентирование в сфере этики и безопасности.
Помимо обеспечения корректности работы, мощные языковые модели поднимают серьезные этические вопросы и вопросы безопасности. Это не просто технические неполадки, которые нужно устранять; это социальные проблемы, требующие тщательного рассмотрения от всех нас.
- Дезинформация: Возможность генерировать реалистично выглядящий текст в массовом масштабе — мечта для любого, кто хочет распространять фейковые новости или пропаганду.
- Аутентичность: Если ИИ может писать так же хорошо, как человек, как мы можем узнать, кто — или что — создало то или иное произведение? Это усложняет наши представления об авторстве и оригинальности.
- Безопасность: Злоумышленники уже изучают возможности использования этих моделей для сложных фишинговых атак, социальной инженерии и других вредоносных действий.
Но не всё так плохо. Эти проблемы находятся в центре внимания исследований в области ИИ. Разработчики постоянно экспериментируют с новыми способами повышения достоверности моделей, уменьшения их предвзятости и внедрения более эффективных функций безопасности. Цель состоит не просто в том, чтобы сделать ИИ более мощным, а в том, чтобы создать системы, которые будут более безопасными, прозрачными и лучше соответствовать человеческим ценностям.
На данный момент лучшее, что вы можете сделать как пользователь, — это помнить об этих ограничениях. Это первый шаг к разумному использованию этой невероятной технологии.
Есть вопросы? У нас есть ответы.
В заключение, естественно, у вас еще остались вопросы. Давайте рассмотрим несколько наиболее распространенных, чтобы все прояснить.
В чём реальная разница между искусственным интеллектом, машинным обучением и языковыми моделями?
Полезно представить их как набор матрешек, вложенных одна в другую.
- Искусственный интеллект (ИИ) — это самая большая и обширная область. Это целая, разветвлённая сфера, посвящённая созданию машин, достаточно умных для выполнения задач, которые обычно требуют человеческого интеллекта.
- Машинное обучение (МО) — это следующая кукла внутри. МО — это особая отрасль искусственного интеллекта, где машина, вместо того чтобы быть запрограммированной на каждый отдельный шаг, учится и совершенствуется самостоятельно, анализируя огромные массивы данных.
- Языковые модели — это самая маленькая, внутренняя кукла. Это специализированный тип машинного обучения, который фокусируется исключительно на одном: понимании, обработке и генерации человеческого языка.
Может ли языковая модель действительно понимать эмоции или контекст?
Это отличный вопрос. Языковые модели не «чувствуют» эмоции так, как мы. У них нет сознания или личного опыта.
Однако невероятно хорошо они умеют распознавать закономерности. Их обучали на миллиардах примеров человеческого текста, поэтому они научились связывать определенные слова, фразы и структуры предложений с конкретными эмоциями, такими как радость, разочарование или сарказм. Это высокоразвитая форма сопоставления закономерностей, а не подлинное понимание эмоций.
Как я могу начать использовать языковые модели в своей работе уже сегодня?
Скорее всего, вы уже это делаете. Если вы пользовались поиском Google, получали подсказки от Grammarly или видели, как ваш почтовый клиент заканчивает ваше предложение, значит, вы взаимодействовали с языковой моделью.
Чтобы подойти к этому более целенаправленно, начните с анализа своих повседневных задач. Есть ли какая-нибудь повторяющаяся, связанная с языком работа, от которой вы хотели бы избавиться? Вы можете рассмотреть варианты использования помощников по написанию текстов на основе ИИ, автоматизированных сервисов транскрипции, таких как Whisper AI , или даже чат-ботов. Ключевой момент — найти конкретную проблему и инструмент, предназначенный для ее решения.
Готовы использовать мощную языковую модель? С Whisper AI вы можете мгновенно расшифровывать и резюмировать аудио- и видеоконтент, превращая часы медиафайлов в точный, полезный текст за считанные минуты. Узнайте, как Whisper AI может преобразить ваш рабочий процесс уже сегодня .