Что такое обработка естественного языка? Руководство для создателей контента.
Вы когда-нибудь пытались заставить умную колонку понимать сарказм? Вы быстро понимаете, что ей нужно улавливать не только сами слова, но и контекст, тон и скрытый смысл. В двух словах, это и есть главная задача обработки естественного языка (NLP) .
НЛП (обработка естественного языка) — это область искусственного интеллекта, которая учит компьютеры читать, понимать и даже генерировать человеческий язык таким образом, чтобы это было действительно полезно. Из моего собственного опыта работы с инструментами ИИ для контента могу сказать, что это технология, которая превращает рутинные задачи в автоматизированные рабочие процессы, освобождая вас от рутинной работы и позволяя сосредоточиться на творческой стороне вопроса.
Что такое обработка естественного языка простыми словами?

Представьте себе НЛП как важнейший мост между нашим сложным, многогранным человеческим языком и жестким, логическим миром компьютера. Человеческое общение полно двусмысленности, идиом и внутренних шуток — всего того, что приводит к сбоям в коде. НЛП дает компьютерам основу для работы в этой сложной системе.
Это как научить компьютер иностранному языку, но вместо того, чтобы просто дать ему словарь, вы учите его грамматике, культурному контексту и умению понимать обстановку. В этом и заключается волшебство бесчисленных инструментов, на которые мы полагаемся ежедневно, часто даже не осознавая этого.
Чтобы было проще разобраться, вот краткий обзор основных идей НЛП и того, как они проявляются в реальном мире.
Обработка естественного языка: краткий обзор
Эти концепции работают вместе, позволяя технологии понимать вашу речь и отвечать осмысленным образом.
Как НЛП проявляется в вашей повседневной жизни
Вы наверняка сегодня использовали НЛП, вероятно, несколько раз. Это незаметный механизм, работающий в фоновом режиме во многих приложениях. Для создателей контента увидеть, где он уже используется, — это первый шаг к тому, чтобы представить его потенциал для собственных проектов.
Вот несколько распространенных мест, где вы его найдете:
- Автокоррекция и предиктивный ввод текста: Когда мой телефон исправляет опечатку или предлагает следующее слово, это означает, что NLP предсказывает мое намерение на основе распространенных фраз и моих собственных привычек письма.
- Фильтры спама в электронной почте: такие сервисы, как Gmail, не просто ищут ключевые слова; они анализируют тон, структуру и цель электронного письма, чтобы определить, является ли оно спамом.
- Голосовые помощники: Когда вы разговариваете с Siri или Alexa, NLP сначала переводит вашу речь в текст, затем определяет, что вы спрашиваете, находит ответ и, наконец, генерирует голосовой ответ.
Обработка естественного языка учитывает иерархическую структуру языка: несколько слов образуют фразу, несколько фраз образуют предложение, и, в конечном счете, предложения передают идеи. Анализируя язык на предмет его значения, системы обработки естественного языка выполняют полезные функции, от исправления грамматики до преобразования речи в текст.
Почему НЛП меняет правила игры для создателей контента
Для тех, кто создает контент, эта технология — гораздо больше, чем просто крутой трюк для вечеринки, это мощный помощник. Она может выполнять рутинные задачи, выявлять ценные идеи от вашей аудитории и, в конечном итоге, помогать вам более эффективно взаимодействовать с людьми.
Интересно, что недавнее исследование показало, что внутренние механизмы моделей ИИ, таких как Whisper AI, удивительно хорошо совпадают с тем, как человеческий мозг обрабатывает речь. Это не просто техническая деталь; именно поэтому современные инструменты обработки естественного языка так хороши в своей работе.
Поскольку они способны обрабатывать язык с определённой степенью контекстного понимания, они могут:
- Расшифровка аудио- и видеоматериалов с исключительной точностью.
- Сформулируйте из длинных интервью или статей краткое содержание в виде пунктов, которые необходимо знать.
- Проанализируйте комментарии аудитории , чтобы выявить повторяющиеся темы и общее настроение.
Понимание того , что такое обработка естественного языка, — это первый шаг к её применению на практике. Суть в том, чтобы превратить прекрасный хаос человеческого языка в структурированную информацию, которая поможет вам создавать более качественные и быстрые продукты.
Эволюция НЛП: от жестких правил к интеллектуальному искусственному интеллекту.
Чтобы по-настоящему понять, на что способна обработка естественного языка сегодня, полезно оглянуться назад и посмотреть, с чего она началась. Это не просто скучный урок истории; это история раннего энтузиазма, серьезных неудач и революционных прорывов, которые привели к появлению современных интеллектуальных инструментов искусственного интеллекта. История обработки естественного языка по-настоящему начинается с оглушительного успеха в 1950-х годах.
Первоначальный ажиотаж начался с эксперимента Джорджтаунского университета и IBM в 1954 году — знакового события, которое создало впечатление, что автоматический перевод уже не за горами. Исследователи из Джорджтаунского университета и IBM поразили публику, переведя более 60 русских предложений на английский язык, используя систему заранее определенных правил. Демонстрация была настолько убедительной, что эксперты с уверенностью предсказывали, что машинный перевод будет решен за три-пять лет. Вы можете глубже погрузиться в этот увлекательный период и его проблемы в этом обзоре истории LLM .
Зима искусственного интеллекта и пределы правил
Конечно, этот первоначальный оптимизм быстро улетучился. Прогресс зашёл в тупик, и основная проблема заключалась в самом подходе. Ранние методы обработки естественного языка строились на так называемом символическом искусственном интеллекте , что означало, что лингвистам приходилось вручную составлять невероятно сложные наборы грамматических правил. Только представьте, каково это — пытаться создать свод правил, охватывающий каждый нюанс английского языка — каждое идиоматическое выражение, каждое исключение, каждое саркастическое замечание. Это поистине невыполнимая задача.
Этот метод, основанный на правилах, был невероятно ненадежным и просто не мог справиться с запутанной и неоднозначной манерой речи и письма людей. Компьютер, которому были введены жесткие правила, мог идеально обработать фразу «Кот сидел на коврике», но совершенно растерялся бы, услышав фразу «Эта новая песня — огонь». Система не обладала способностью понимать контекст или учиться на новой информации.
Чрезвычайная сложность человеческого языка быстро поставила эти ранние системы в тупик. К 1966 году влиятельный доклад ALPAC вынес отрезвляющий вердикт: после многих лет исследований и миллионов долларов финансирования машинный перевод по-прежнему был медленнее, дороже и менее точным, чем переводы, выполняемые людьми. Доклад фактически положил начало первой «зиме ИИ» — длительному периоду, когда финансирование иссякло, а прогресс в языковых технологиях остановился.
Эта неудача стала критическим поворотным моментом. Она заставила всю отрасль переосмыслить всё. Главный урок заключался в том, что обучение компьютера языку — это не то же самое, что дать ему словарь и грамматический справочник. Речь идёт о том, чтобы дать ему возможность учиться на собственном опыте, подобно человеку.
Статистическая революция меняет всё.
Следующий гигантский шаг вперед произошел в 1980-х и 1990-х годах с переходом к статистической обработке естественного языка . Вместо того чтобы пытаться писать идеальные, созданные вручную правила, исследователи пошли совершенно другим путем. Они начали загружать в компьютеры огромные объемы текста — книги, статьи и новостные сообщения — и позволять им самостоятельно выявлять закономерности. Это был фундаментальный сдвиг от программирования правил к обучению на основе данных.
Анализируя, как слова и фразы встречаются вместе в миллионах документов, эти новые статистические модели могли делать обоснованные предположения. Они могли предсказывать наиболее вероятное слово, следующее за другим, выявлять общие темы в тексте и даже определять эмоциональную окраску предложения. Этот подход, основанный на данных, оказался гораздо более устойчивым и гибким, проложив путь к мощным инструментам обработки естественного языка, на которые сегодня полагаются создатели контента и профессионалы.
Как компьютеры понимают язык?
Вы когда-нибудь задумывались, как компьютер переходит от просмотра блока текста к его пониманию ? Это не магия, но он следует логическому пути, который удивительно похож на то, как мы изучаем новый язык. Нужно начать с основ — букв, слов, грамматики — прежде чем можно будет перейти к чему-то более важному, например, к пониманию шуток или анализу стихов.
Для компьютера этот путь начинается с того, что он берет наш сложный, многогранный человеческий язык и разбивает его на мельчайшие, поддающиеся анализу фрагменты. Оттуда он слой за слоем выстраивает свое понимание. Он переходит от простого распознавания отдельных слов к пониманию сложных идей, таких как контекст, эмоции и намерения.
Этот процесс позволяет превратить сумбурную стенограмму интервью в лаконичное резюме или быстро просмотреть тысячи документов в поисках ключевых имен и мест. Все это стало возможным благодаря эволюции от неуклюжих, устаревших систем к современному сложному искусственному интеллекту.
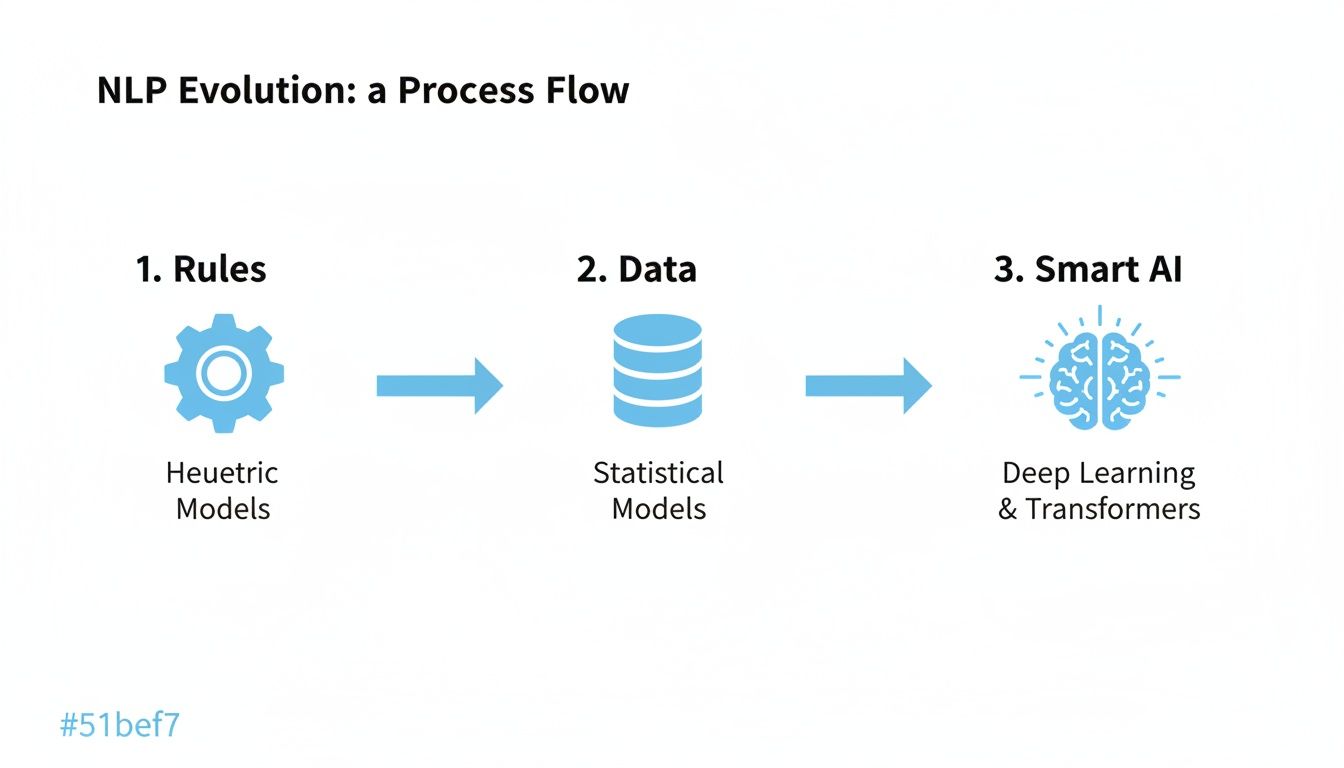
Как видите, мы перешли от жестких, написанных вручную правил к системам, которые обучаются на основе огромных массивов данных, а теперь и к современному искусственному интеллекту, который практически способен мыслить самостоятельно.
Разложение предложений на основные компоненты
Первая задача любой модели обработки естественного языка — разбить предложение на управляемые части. Это называется токенизацией . Представьте себе, что компьютер учится азбуке и словарю.
Программа берет предложение типа "Этот эпизод подкаста просто фантастический!" и разбивает его на отдельные слова или "токены". В результате получается что-то вроде: ["This", "podcast", "episode", "is", "fantastic", "!"] .
После токенизации предложения искусственному интеллекту необходимо определить функцию каждого слова. Именно здесь вступает в игру разметка частей речи (POS-тегирование) . Это своего рода урок грамматики. Компьютер присваивает каждому токену метку, определяя его как существительное, глагол, прилагательное и так далее.
- Существительное:
podcast,episode - Глагол:
is - Прилагательное:
fantastic - Пунктуация:
!
Эта грамматическая основа является фундаментом для всего остального. Именно она позволяет системе перейти от простого распознавания слов к пониманию их структурной взаимосвязи, обеспечивая работу всего, от базовых грамматических проверок до сложного анализа. Чтобы подробнее узнать, как это применяется к устной речи, ознакомьтесь с нашим руководством о том, как работает искусственный интеллект для преобразования голоса в текст .
От грамматики к пониманию смысла
Обладая хорошим знанием грамматики, система обработки естественного языка наконец-то может начать понимать, что на самом деле означает текст. Именно здесь кроется её настоящая ценность. Цель состоит в том, чтобы определить не только то, что означают слова, но и то, что они представляют в реальном мире.
По своей сути, обработка естественного языка направлена на то, чтобы выйти за рамки рассмотрения текста как просто последовательности символов. Анализируя иерархическую структуру языка, где слова образуют фразы, а предложения передают идеи, системы обработки естественного языка могут выполнять действительно полезные функции.
Одним из наиболее эффективных методов является распознавание именованных сущностей (NER) . В этом методе искусственный интеллект учится выявлять и классифицировать важные фрагменты информации в тексте, подобно детективу, извлекающему ключевые улики.
- Люди: «Илон Маск», «Опра Уинфри»
- Организации: «Google», «Красный Крест»
- Места съемок: «Нью-Йорк», «Эверест»
- Даты: «26 октября», «следующий вторник»
Еще один важный навык — анализ настроений , позволяющий компьютеру «читать» обстановку. Изучая выбор слов и контекст, модель может определить, является ли текст — например, отзыв клиента или сообщение в социальных сетях — позитивным, негативным или нейтральным . Это невероятно полезно для создателей контента и брендов, которым необходимо оценивать отзывы аудитории в больших масштабах, не читая вручную тысячи комментариев.
В совокупности эти шаги позволяют НЛП преодолеть разрыв между простым чтением слов и истинным пониманием заложенного в них смысла.
Теперь, когда мы заглянули под капот и рассмотрели механику НЛП, давайте поговорим о том, что действительно важно: как вы можете использовать её на практике. Теория интересна, но настоящая магия происходит, когда эта технология экономит ваше время, открывает новые горизонты и предоставляет творческие возможности, которых у вас раньше не было.
Для всех, кто сегодня создает контент, НЛП уже меняет правила игры. Она превращает самые рутинные части нашей работы в автоматизированные, практически не требующие усилий процессы.
От звукового хаоса к упорядоченному контенту
Если вы подкастер или ютубер, вы знаете, как это бывает. Вы заканчиваете потрясающее двухчасовое интервью, и следующий шаг — это гора работы: часы ручной расшифровки диалогов, повторное прослушивание в поисках лучших цитат, а затем попытка превратить это в рекламный материал. Это изнурительная работа.
Современные инструменты обработки естественного языка полностью меняют этот подход. Теперь вам достаточно загрузить аудио- или видеофайл, и сервис на основе искусственного интеллекта сделает за вас всю сложную работу.
Как это выглядит на практике? Искусственный интеллект может «прослушать» вашу запись и за несколько минут создать удивительно точную расшифровку с указанием времени. Но речь идёт не просто о записи текста на бумаге. Речь идёт о том, чтобы сделать ваш аудио- и видеоконтент мгновенно доступным для поиска, удобным для использования и готовым к повторному применению.
Внезапно это двухчасовое интервью превращается в:
- Быстрая публикация в блоге: расшифровку можно быстро отредактировать и превратить в подробную статью, готовую для вашего сайта и оптимизированную для поисковых систем.
- Основные моменты, которыми можно поделиться: Искусственный интеллект может выявлять наиболее интересные моменты разговора и генерировать краткие резюме или тезисы в виде пунктов. Они идеально подходят для заметок к выпускам, рассылок по электронной почте или публикаций в социальных сетях за целую неделю. Вы можете увидеть, как видеоредактор превращает длинный контент в короткие ролики, чтобы дать более полное представление.
- Поиск цитат без усилий: Помните ту самую удачную фразу вашего гостя? Вместо того чтобы 20 минут просматривать хронологию, вы можете просто использовать "Ctrl+F" в стенограмме и найти её за считанные секунды.
Раскрытие секретов в ваших данных
Для журналистов, исследователей и маркетологов НЛП — это как сверхспособность находить иголку в стоге сена. Ручной анализ тысяч документов, отзывов клиентов или комментариев в социальных сетях — задача невыполнимая. НЛП автоматизирует этот процесс, выявляя тенденции и извлекая важную информацию со скоростью, недоступной человеку.
Прекрасный пример этому — анализ настроений . Вместо того чтобы просто гадать, как мое последнее видео было воспринято аудиторией, я могу получить подкрепленную данными картину их эмоциональной реакции. Можно извлечь комментарии на YouTube для анализа настроений и увидеть, что на самом деле думает моя аудитория, помимо простого количества лайков и просмотров.
Это означает, что маркетологи могут отслеживать восприятие бренда в режиме реального времени, анализируя упоминания в социальных сетях, а журналисты могут просматривать огромные массивы просочившихся документов, чтобы за считанные минуты, а не месяцы, выявлять ключевые имена и связи. Раньше это было ручное чтение; теперь — поиск информации с помощью искусственного интеллекта.
В таблице ниже показано, как различные задачи обработки естественного языка напрямую преобразуются в мощные функции, которые создатели контента могут использовать для оптимизации своей работы и более глубокого понимания своей аудитории.
Методы НЛП и их влияние на контент
Каждый из этих методов превращает сложную, трудоемкую ручную задачу в быстрый автоматизированный процесс, освобождая вас от рутинной работы и позволяя сосредоточиться на том, что у вас получается лучше всего: создании качественного контента.
Как Whisper AI использует обработку естественного языка в ваших интересах

Одно дело — говорить о НЛП в теории, и совсем другое — видеть, как она решает реальные проблемы. Для создателей это тот момент, когда практика переходит в практику. Такие инструменты, как Whisper AI, берут сложный механизм языковых моделей и превращают его в практические решения, которые экономят время и порождают новые идеи.
Подумайте об этом так: вместо того, чтобы быть просто академическим термином, обработка естественного языка становится ответом на проблему бесконечного потока контента. Представьте, что вы превращаете часовое интервью в подкасте в идеальную стенограмму, список цитат и десяток постов в социальных сетях — всего за несколько минут. Это и есть обработка естественного языка в действии, возвращающая вам ваш самый ценный ресурс: время.
Высочайшая точность транскрипции
В основе Whisper AI лежат мощные модели преобразования речи в текст, обеспечивающие невероятно точную транскрипцию. Речь идёт не о простом дословном преобразовании. Искусственный интеллект специально обучен справляться со сложными особенностями аудиопроизводства, где другие сервисы часто терпят неудачу.
Он особенно хорошо справляется со следующими задачами:
- Сильный фоновый шум или некачественное звучание.
- Несколько говорящих , даже если они говорят, перебивая друг друга.
- Выраженный региональный акцент и быстрый темп разговора.
Такой уровень надежности является прямым результатом фундаментального сдвига в области обработки естественного языка, начавшегося несколько десятилетий назад. Еще в 1980-х и 90-х годах эта область отошла от жестких, основанных на правилах систем, которые давали сбой в 80-90% случаев при обработке реальных предложений, в сторону моделей, основанных на данных. Эти новые системы обучались на огромных массивах текста, что привело к таким прорывам, как скрытые марковские модели (HMM), которые повысили точность распознавания речи на 30-50% .
Именно эта эволюция от правил, написанных вручную, к статистическому обучению позволяет Whisper AI различать говорящих в интервью или добавлять точные временные метки к вашему видео. Речь идёт не просто о слышании слов; речь идёт об их понимании в контексте.
От многочасового аудиоконтента до мгновенных лучших моментов
Whisper AI выходит далеко за рамки простой транскрипции. Платформа использует передовые методы суммаризации, чтобы выделить наиболее важные идеи в вашем контенте. Она не просто сокращает количество слов; она определяет основные аргументы и организует их в понятные, удобные форматы.
Благодаря поддержке более 90 языков и твердой приверженности принципам конфиденциальности данных, Whisper AI делает мощную обработку естественного языка практичной и безопасной для создателей контента по всему миру.
Это означает, что вы можете мгновенно создать краткое резюме, маркированный список основных моментов или перечень ключевых обсуждаемых тем. Для тех, кто стремится поддерживать постоянное присутствие в интернете, возможность так быстро перерабатывать контент является огромным преимуществом.
Хотите узнать больше? Вы можете ознакомиться с подробным обзором работы Whisper AI .
Будущее НЛП и связанные с ним вызовы
Обработка естественного языка прошла долгий путь, но важно сохранять хладнокровие. Технология впечатляет, но это не волшебство. Чтобы по-настоящему понять , что такое обработка естественного языка , мы должны взглянуть на ее шероховатости — существующие ограничения и серьезные этические вопросы, которые с ней связаны.
Даже самые сложные модели ИИ могут споткнуться о те самые вещи, которые делают человеческий язык таким богатым. Сарказм, шутки, понятные только членам одной культуры, и разговоры, в значительной степени основанные на общем контексте, могут пройти мимо них. Это происходит потому, что эти модели обучаются на огромных массивах данных, и если эти данные искажены, то и результат работы ИИ будет искажен.
Одна из самых больших проблем для НЛП — это борьба с предвзятостью, заложенной в обучающих данных. Если модель изучает язык преимущественно у одной конкретной группы людей, ей будет трудно понимать — или, что еще хуже, она будет искажать — язык других групп, увековечивая при этом вредные стереотипы.
Помимо предвзятости, сам факт использования наших данных для обучения этих систем поднимает сложные вопросы, касающиеся конфиденциальности. По мере того, как обработка естественного языка все больше интегрируется в наши повседневные инструменты и привычки, вопрос ответственного обращения с персональными данными становится проблемой, которую мы не можем игнорировать.
Что ждет искусственный интеллект в будущем в области лингвистики?
Несмотря на эти препятствия, предстоящий путь действительно захватывающий. Следующие крупные прорывы уже начинают формироваться, и их развитие во многом обусловлено двумя основными разработками: моделями обработки больших языков следующего поколения (LLM) и мультимодальным искусственным интеллектом .
Мультимодальный ИИ — это огромный шаг вперед, поскольку он способен обрабатывать и объединять информацию из разных источников одновременно — текст, изображения, аудио и видео — подобно тому, как это делает наш собственный мозг. Эта возможность откроет совершенно новый класс инструментов для творчества.
- Гиперперсонализированный опыт: представьте себе искусственный интеллект, способный анализировать взаимодействие вашей аудитории с вашими видео, подкастами и статьями, чтобы помочь вам создавать контент, который действительно находит отклик у аудитории.
- Расширенная генерация контента: представьте себе искусственный интеллект, который может посмотреть одно из ваших видео, прослушать аудиозапись, а затем написать пост в блоге, идеально отражающий его тему, и даже предложить соответствующие изображения.
- Более глубокий анализ: сопоставляя комментарии пользователей с конкретными моментами видео, вызвавшими эти реакции, создатели контента могут получить гораздо более четкое представление о том, что нравится их аудитории.
Заглядывая в будущее, становится ясно, что влияние революции в области искусственного интеллекта на рынок труда и экономику будет значительным. По мере совершенствования обработки естественного языка (NLP) она призвана изменить не только способы создания контента, но и основы целых отраслей.
Ответы на ваши вопросы по НЛП
В заключение, естественно, у вас останутся некоторые вопросы. Давайте рассмотрим некоторые из наиболее распространенных, которые возникают, когда люди только начинают осваивать обработку естественного языка.
NLP — это просто другое название для искусственного интеллекта?
Не совсем, но они тесно связаны. Хороший способ представить это — вообразить искусственный интеллект (ИИ) как огромную, разветвленную область исследований — всю науку о том, как сделать машины умными. В рамках этой обширной области обработка естественного языка (ОБЯ) — это специализированная дисциплина, полностью сосредоточенная на языке.
Таким образом, хотя каждое приложение обработки естественного языка (NLP) является разновидностью искусственного интеллекта, не весь ИИ работает с языком. Например, навигационная система беспилотного автомобиля — это ИИ, но это не NLP.
Как я могу реально использовать НЛП для создания контента?
Скорее всего, вы уже знакомы с НЛП! Если вы когда-либо пользовались программой проверки грамматики, видели, как социальная сеть анализирует настроения комментариев, или использовали автокоррекцию на своем телефоне, вы уже получили пользу от НЛП.
Для создателей контента и журналистов, стремящихся к большему, не требуется диплом по информатике. Такие платформы, как Whisper AI, созданы для того, чтобы сделать эту технологию доступной. Вы можете расшифровать многочасовые интервью или составить краткое содержание длинного подкаста всего несколькими кликами. Просто загрузите свой файл, и модели обработки естественного языка (NLP) выполнят всю сложную работу в фоновом режиме, предоставляя точные расшифровки и краткие резюме за считанные минуты.
Для многих создателей контента ключевой проблемой является конфиденциальность данных. Некоторые сервисы могут использовать ваш контент для обучения своих моделей искусственного интеллекта, поэтому выбор платформы с прозрачной политикой конфиденциальности так важен.
Какие риски для конфиденциальности мне следует опасаться?
Это действительно важный вопрос, и ответ на него зависит от выбранного вами поставщика. Ваш контент — это ваша интеллектуальная собственность, поэтому вам нужно тщательно выбирать, кому вы его доверяете.
Вот почему вам всегда следует читать политику конфиденциальности. В Whisper AI мы создали наш сервис, в основе которого лежит конфиденциальность. Мы безопасно обрабатываем ваши файлы, никогда не используем ваши данные для обучения наших моделей и не храним ваши файлы дольше, чем необходимо. Ваш контент всегда остается вашей собственностью.
Готовы узнать, как ИИ может оптимизировать ваш рабочий процесс с контентом? Попробуйте Whisper AI сегодня и получите первую расшифровку и резюме за считанные минуты. Посетите наш веб-сайт, чтобы начать .